








Table of contents
Building an effective data pipeline architecture is challenging, especially when enterprise requirements – like scale, speed, and security – are taken into account.
Table of Contents
Data Pipeline Architecture Planning
Data Pipeline Architecture Challenges
Data Pipeline Architecture Considerations
Building a Better Data Pipeline Architecture with Data Products
Data Pipeline Architecture Planning
We’ve discussed the importance of a data pipeline in connecting between multiple data sources and targets. What is a data pipeline, if not helping organizations prepare, transform and deliver data - and then providing them with the ability to add advanced automation capabilities to make the entire process quicker, easier and more accurate.
But for all that to happen, enterprises must plan the right data pipeline architecture – taking into account key challenges and considerations.
Data Pipeline Architecture Challenges
The data pipeline architecture should answer current data demands and the issues that stem from them. Chances are that the company would need to extract data from multiple sources and in various formats. This data should be collected from across the organization, processed, enriched, masked, and more.
Supporting these efforts, at scale, is a daunting task for enterprises, and when adding compliance regulations and system vulnerabilities, the challenges are compounded.
Data engineers are hard pressed to oversee the execution process, while adapting to changes along the way.
Data Pipeline Architecture Considerations
The following factors determine your ability to successfully meet your data pipeline goals:
-
Support for a wide variety of data sources and delivery modes
Multiple data sources aren’t the only thing you’ll need to support, but also different data formats and system technologies. The key here is versatility and adaptability.
Enterprise IT often must contend with dozens of data sources, from multiple technologies, with different data structures, and a lack of data cataloging and lineage.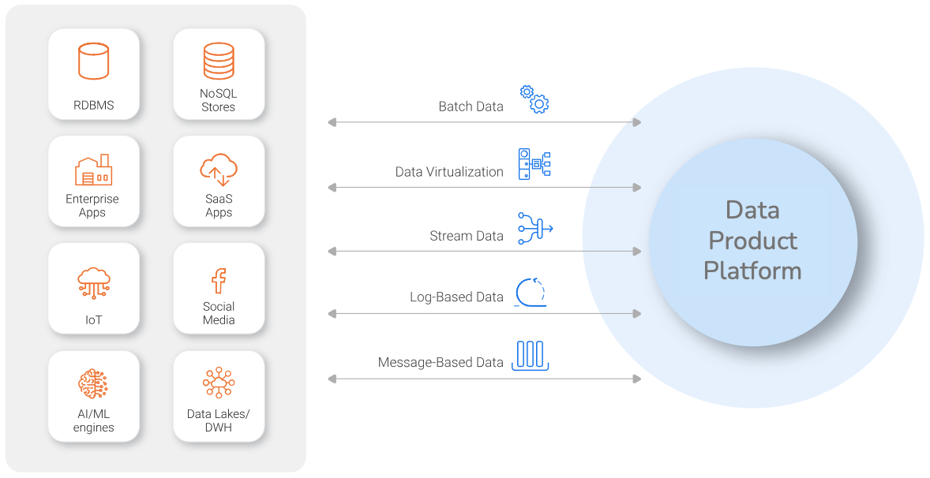 A Data Product Platform makes data pipeline architecture more versatile and adaptable.
A Data Product Platform makes data pipeline architecture more versatile and adaptable.
The long list of data sources includes:-
RDBMS like SQL Server, Oracle, PostgreSQL, DB/2, and more
-
SQL stores such as Redis, MongoDB, Cassandra, and Google Cloud Datastore
-
On-premise enterprise applications including mainframes and client/server combos
-
Cloud-based SaaS applications, secure FTP, SMTP for access to unstructured email data
-
Data lakes, data warehouses, AI and machine learning engines, and more
-
Batch, based on high-scale extract or ETL facilities
-
Data virtualization, using a logical abstraction layer to address underlying system complexities and offer real-time business data access
-
Stream data integration, that enables organizations to ingest, transform, and deliver real-time event data that boosts customer experience, security, and operational efficiency.
-
Log-based incremental replication, that harnesses Change Data Capture (CDC) capabilities to adapt to real-time database changes.
-
Message-oriented data movement, that brings together data from various messages to produce usable messaging formats.
-
-
Batch vs real-time data streaming
Batch data pipelines deliver data in bulk, as a whole, to target systems. This approach is most relevant when intermittent latency is involved, or when the data isn’t considered particularly urgent – for example, with analytical workloads, where data scientists need the data in a data lake or data warehouse for analytics.
Real-time data pipelines - whether based on real-time data streams, messages, or log-based changes - place incoming data in temporal storage for processing (such as identity resolution), creating an infinite live feed that sends micro-batches based predefined logic. Like a fire fighter, IT chooses between batch (tanker) or streaming (hydrant) delivery.
Like a fire fighter, IT chooses between batch (tanker) or streaming (hydrant) delivery.Since different workloads may require different data delivery methods, the data pipeline architecture must support the various real-time and batch data delivery styles.
-
Support basic and advanced data transformation
Data transformation is a process that helps prepare the data extracted from various sources to fit the format that the data consumer expects to receive. This procedure includes data cleansing, masking, and enrichment, and is performed in-flight or in batch, based on the chosen data delivery approach.
We’ve long talked about the different processing methods of ETL and ELT, for example. The former includes pre-loading transformation steps, while the latter first loads the unprocessed data and applies transformation rules later. -
Data catalog and data governance requirements
Wherever data privacy is involved, maintaining high compliance and security standards is critical. That’s where data catalog and data governance comes into play.
A data catalog helps teams manage the data, through its data lineage, and identifies any sensitive information that should be protected and masked. It uncovers the relationships between different data entities, making them easy to manipulate, and revealing any sensitive elements that might have otherwise flown under the radar.
The data pipeline architecture’s governance capabilities should include automated processing that quickly adapts to the latest regulations using simple configuration changes. This allows the enterprise to to protect itself in today’s ever-changing data privacy landscape. -
Time travel
Your data pipeline architecture should support a time machine, a must-have feature of automated data preparation, that enables data teams to return to earlier datasets, with full access to historical data versions. This way, they can move forward, knowing that their previous work is safely stored, and available, whenever it's needed. -
Enterprise requirements
The enterprise data pipeline has special requirements:-
Scalability
Your data pipeline architecture must be able to support the continued exponential growth in the volume of data - both structured and unstructured. Expanding or narrowing data volume shouldn’t influence the data quality or availability. -
Performance
Agile enterprises move fast, and their data pipeline needs to keep up. This relates to scale, but also to high-speed processing involved in data preparation, and the ability to change data pipelining logic on the fly. -
Security and privacy
Enterprise-grade data specifications must include the masking of sensitive data according to the latest data privacy compliance demands and the most stringent security measures. -
Reliability
The data pipeline must be available and reliable, offering mechanisms that validate and audit data delivery from sources to targets.
-
Building a Better Data Pipeline Architecture with Data Products
A Data Product Platform fulfills the core needs of an enterprise data pipeline, allowing companies to build an effective architecture with minimal effort. The data pipeline architecture can be deployed as a data mesh, or data fabric – in the cloud (iPaaS), on premises, or across hybrid rnvironments.
When data is organized by data product, it is much easier to configure, manage, monitor and adapt. A more agile and reliable process is established, allowing enterprises to become more adept, agile and responsive to changing business needs.

