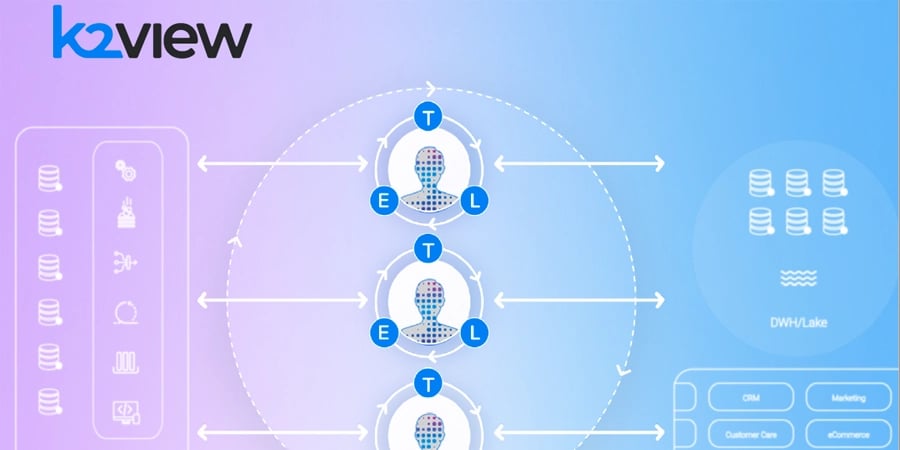
Integrate and deliver anywhere
Leverage AI to integrate and deliver data from any data source – on-prem or cloud – to any data consumer, using any data delivery method: bulk or reverse ETL, data streaming, data virtualization, CDC, message-based data integration, and APIs.
AI automation and active metadata

AI automation copilot 
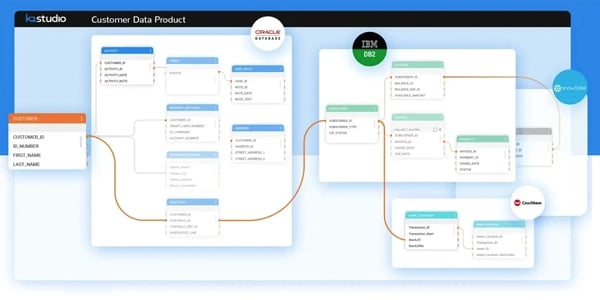
Auto-discover and model your data products.
Auto-classify, generate, and document your data pipelines.
Pipeline auto-recovery
Automatically recover your data pipelines after failures without data loss, for seamless data ingestion and integration.
Schema drift prevention
Auto-detect changes, perform impact analysis, and provide recommendations and actions for continuous integration.
Self-optimization
Analyze metadata to continuously improve resilience, optimize data integration performance, and control costs.
.png?width=657&height=426&name=integration%20(1).png "Entity-based Data Integration Tools")