





A practical guide to synthetic data generation tools
What is Synthetic Data Generation?
Last updated on January 26, 2026

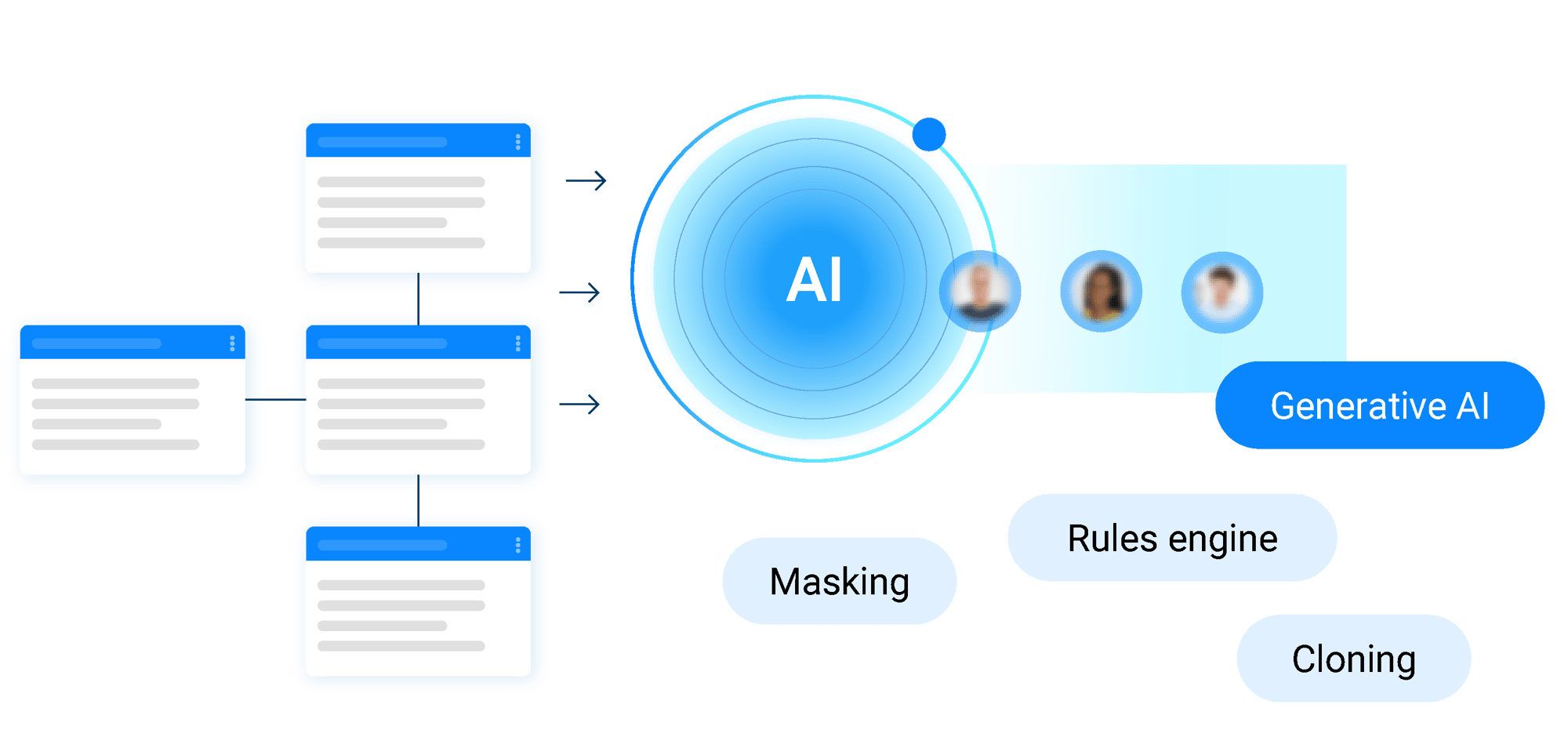

 Table of Contents
Table of Contents
Synthetic data generation is the process of creating artificial data that mimics the features, structures, and statistical attributes of production data, while maintaining compliance with data privacy regulations.
02
What is synthetic data generation?
Synthetic data generation is the process of creating artificial data that mimics the statistical patterns and properties of real-life data using algorithms, models, and other techniques.
Even though it’s usually based on real data, fake data often contains no actual values from the original dataset.
Unlike real data, which may contain sensitive or Personally Identifiable Information (PII), fake data ensures data privacy, while enabling data analysis, research, and software testing.
The 4 key synthetic data generation techniques are listed below:
-
Generative AI – modeled using Generative Pre-trained Transformers (GPT), Generative Adversarial Networks (GANs), or Variational Auto-Encoders (VAEs) – learns the underlying distribution of real data to generate similarly distributed synthetic data.
-
A rules engine creates artificial data via user-defined business rules. Intelligence can be added to the generated data by referencing the relationships between the data elements, to ensure the relational integrity of the generated data.
-
Entity cloning extracts data from the source systems of a single business entity (e.g., customer) and masks it for compliance. It then clones the entity, generating different identifiers for each clone to ensure uniqueness.
-
Data masking replaces PII with fictitious, yet structurally consistent, values. The objective of data masking is to ensure that sensitive data can’t be linked to individuals, while retaining the overall relationships and statistical characteristics of the data.
These 4 techniques are discussed in greater detail in chapter 6.
Here are some other, less common methods:
-
Copula models discover correlations and dependencies within the production data sets, and then use them to generate new, realistic data.
-
Data augmentation applies supplementary techniques – such as flipping, rotation, scaling, and translation – to existing values to create new data.
-
Random sampling and noise injection add random sampling data points from known distributions, as well as noise to existing data, to create new data points that closely resemble real-world data.
Our 2026 State of Enterprise Data Compliance survey shows that enterprise compliance weakens sharply once data leaves production. Only 13% safeguard PII in AI systems, while 76% experienced a sensitive-data incident in lower environments.

03
What are common synthetic data generation use cases?
There are 2 primary use cases that rely on synthetic data solutions:
-
Software testing needs compliant synthetic test data provisioned to test environments, to ensure that the applications being developed perform as expected.
-
Machine Learning (ML) model training relies on synthetic data generation to supplement existing datasets when production data is scarce or non-existent.
Each of these synthetic data use cases will be discussed in greater detail in chapters 4 and 5.
Additional use cases include:
-
Privacy-compliant data sharing uses fictitious data to distribute datasets internally (to other domains) or externally (to partners or other authorized third parties) without revealing PII. Good examples of this are synthetic financial data and synthetic patient data.
-
Product design deploys fake data to provide standardized benchmarks for evaluating product performance in a controlled environment.
-
Behavioral simulations employ artificial data to explore different scenarios, validate models, and test hypotheses without using real-life data.
In our recent survey of 300 data pros, 53% of companies listed edge case testing as their top use case for synthetic data:

Top use cases for synthetic data

Edge case testing, by industry
Source: K2view 2025 State of Test Data Management report
Financial service providers, such as banks and insurance companies, lead the way in synthetic data adoption, particularly for edge case testing.
Manage the entire AI-Powered synthetic data lifecycle


09
What are the top synthetic data tools for 2026?
There are many providers of tabular synthetic data generation software. The market is continually evolving, with vertical specialization tools, pure-play horizontal platforms, and extensions of existing data management platforms.
Here's a list of the top 6 synthetic data companies:
-
K2view

K2view goes beyond synthetic data generation with end-to-end management of the entire synthetic data lifecycle, including source data extraction, subsetting, pipelining, and synthetic data operations. It uses a combination of techniques to generate accurate, compliant, and realistic synthetic data for software testing and ML model training. Patented entity-based technology ensures referential integrity of the generated data by creating a schema which serves as a blueprint for the data model. K2view has been successfully implemented in numerous Fortune 500 companies around the world.-Dec-26-2024-01-43-38-3744-PM.png?width=1950&height=924&name=image%20(5)-Dec-26-2024-01-43-38-3744-PM.png)

- Gretel

Gretel provides a synthetic data platform for developers and ML/AI engineers who use the platform's APIs to generate anonymized and safe synthetic data while preserving data privacy.
-
MOSTLY AI

The MOSTLY AI synthetic data platform enables enterprises to unlock, share, fix, and simulate data. Although similar to actual data, its synthetic data retains valuable, granular-level information, while assuring private information is protected.
-
Syntho

The Syntho AI-based engine generates a completely new, artificial dataset that reproduces the statistical characteristics of the original data. It allows users to minimize privacy risk, maximize data utility, and boost innovation through data sharing.
-
YData

The YData data-centric platform enables the development and ROI of AI applications by improving the quality of training datasets. Data teams can use automated data quality profiling and improve datasets, leveraging state-of-the-art synthetic data generation.
-
Hazy

Hazy models are capable of generating high quality synthetic data with a differential privacy mechanism. Data can be tabular, sequential (containing time-dependent events, like bank transactions), or dispersed through several tables in a relational database.
10
What is the future of synthetic data?
Synthetic data generation processes and solutions are evolving at a rapid pace. The following areas promise to introduce innovation that delivers better business outcomes across synthetic data use cases.
-
Synthetic data operations
The generation of artificial data is just one step in the synthetic data lifecycle. Data teams are now seeking methods and solutions to manage and automate the entire synthetic data lifecycle.
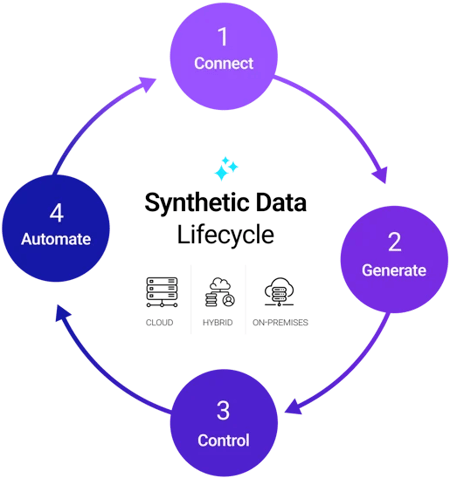
The synthetic data lifecycle can be divided into 4 basic phases:
1. Connect to data sources and discover PII automatically.
2. Generate the right synthetic data for each test case on demand.
3. Control the generated data via reserving, aging, versioning, and rollback techniques.
4. Automate your testing workflows by integrating synthetic data into your CI/CD pipelines.
-
Improved data quality, accuracy, and reliability
Since data professionals rely on accurate and high-quality data for their workloads, synthetic data companies will be driven to continually optimize their synthetic data generation algorithms, and solutions will emerge that generate vertical-specific synthetic data.
-
Ethical and legal perspectives
With the spread of synthetic data, legislators and regulators are paying more attention to its ethical and legal implications. IT and business teams need to be aware of these issues, and take them into account, as they develop.
-
Integration with production data
By integrating fake data with real-life data, data teams hope to generate more realistic and comprehensive datasets. For example, fake data could be used to close any gaps in actual datasets, augment real-life information to cover a broader scope of edge cases, and create test data to cover new application functionality being developed.
-
Emerging use cases
Fictitious data is increasingly being used in new applications, such as autonomous automobiles and virtual reality. Researchers are exploring how artificial data can be used to improve the performance of AI systems in these, and other, emerging technologies.

.jpg?width=506&height=298&name=Generating%20Realistic%20Synthetic%20Data%20with%20GenAI%20(2).jpg)





