-
Platform

-
Solutions

-



🎉 K2view named a Visionary in Gartner’s latest Magic Quadrant for Data Integration





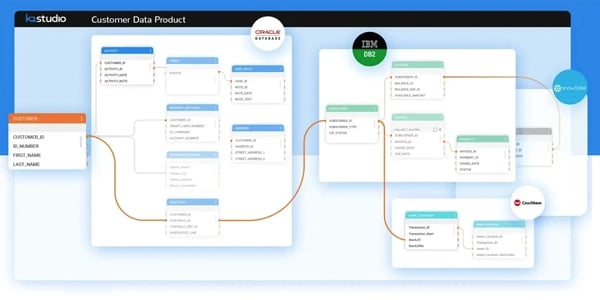
.png?width=600&name=virtual%20(1).png "Data virtualization tools for processing and enriching data")




.webp?width=900&height=450&name=Data%20Virtualization%20Guide%20(1).webp)