





The Practical Guide
What is Data Mesh?
Updated January 8, 2025



 Table of Contents
Table of Contents
Data mesh is a decentralized data management architecture and operating model, which relies on 4 principles: Data products, domain ownership, instant access, and federated governance.

03
What are data products?
Data products are created to be consumed with a specific purpose in mind. A data product may assume a variety of forms, based on the specific business domain or use case to be addressed.
A data product will often correspond to a dataset of one or more business entities – such as customer, asset, supplier, order, credit card, campaign, etc. – that data consumers would like to access for analytical and operational workloads. The data will typically originate in dozens of siloed source systems, often of different technologies, structures, formats, and terminologies.
A data product, therefore, encapsulates everything that a data consumer requires in order to derive value from the business entity's data. This includes the data product's:
-
Metadata, both static and active (usage and performance)
-
Algorithms, for processing the ingested, raw data (data integration, transformation, cleansing, augmentation, anonymization)
-
Data, ready to be delivered or consumed by authorized users
-
Access methods, such as SQL, JDBC, web services, streaming, CDC,...
-
Synchronization rules, defining how and when the data is synced with the source systems
-
Data governance policies, for data quality and privacy
-
Audit log, of data changes
-
Access controls, including credential checking and authentication
The data product lifecycle
A data product is created by applying cross-functional, product lifecycle methodology to data.
The data product lifecycle adheres to the agile principles of being short and iterative, delivering quick, incremental value to data consumers.
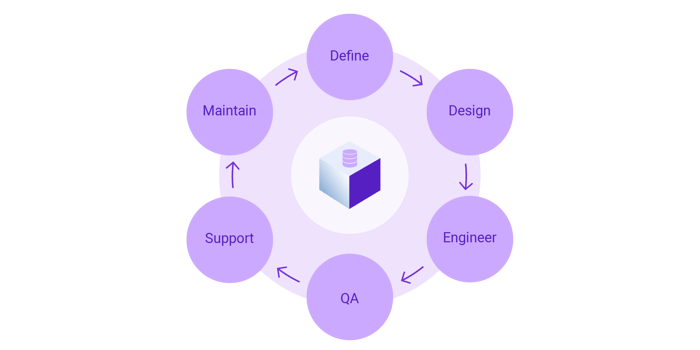
The data product lifecycle includes the following phases:
Definition and design
Data product requirements are defined in the context of business objectives, data privacy and governance constraints, and existing data asset inventories. Data product design depends on how the data will be structured, and how it will be componentized as a product, for consumption via services.
Engineering
Data products are engineered by identifying, integrating, and collating the data from its sources, and then employing data masking (aka data anonymization) as needed.
Web service APIs are created to provide consuming applications with the authority to access the data product, and pipelines are secured for delivering the data to its constituents.
Quality assurance
The data is tested and validated to ensure that it’s complete, compliant, and fresh – and that it can be securely consumed by applications at massive scale.
Support and maintenance
Data usage, pipeline performance, and reliability are continually monitored, by local authorities and data engineers, to so issues can be addressed as they arise.
Management
Just as a software product manager is responsible for defining user needs, prioritizing them, and then working with development and QA teams to ensure delivery, the data product approach calls for a similar role. The data product manager is responsible for delivering business value and ROI, where measurable objectives – such as response times for operational insights, or the pace of application development – have definitive goals, or timelines, based on SLAs reached between business and IT.




