









Table of contents
More than 80% of enterprises consider data integration a critical component in their ongoing business operations, so choosing the right way to integrate data is a particularly important decision.
Data integration takes on different forms, with 2 of the more common ones being Extract-Transform-Load (ETL) and Extract-Load-Transform (ELT) methodology. Data engineers often debate which approach is better for the company’s data pipeline, presenting the advantages and disadvplatantages to consider.
A famous Polish proverb says, “Where 2 are fighting, a 3rd one wins.”
In this article, we’ll discuss what makes ETL vs ELT, better or worse, for data pipelining, only to surprise you with a 3rd, superior, option, eETL, that offers an entity-based approach to data pipelines.
Table of Contents
What is a Data Pipeline?
The Traditional Option: Extract-Transform-Load (ETL)
Emerging from the Clouds: Extract-Load-Transform (ELT)
When it Comes to ETL, Entity-Based Wins the Race
eETL Advantages
Transitioning to eETL
What is a Data Pipeline?
A data pipeline is a series of data processing steps. If the data has not yet been extracted from the data sources, it is first ingested at the start of the pipeline. Afterwards, there is a series of steps in which each step delivers an output, that, in turn, becomes the input for the next step. This construction continues until the pipeline is complete and the data is loaded to the target data store.
Big data pipelines are data pipelines built to accommodate the 3 primary characteristics of big data:
Velocity: The velocity of big data makes data streaming pipelines attractive, in order to enable real-time data capture and processing on the fly.
Volume: The volume of big data requires that the pipelines be scalable. Because millions of data queries may occur simultaneously, the pipelines should be able to scale, to process huge volumes of data concurrently.
Variety: The variety of big data requires the pipelines be able to recognize and process data in many different formats – structured, unstructured, and semi-structured – and aggregate fractured data from many different sources, an technologies (databases, files, enterprise applications, etc.)
The Traditional Option: Extract-Transform-Load (ETL)
The traditional ETL data integration method has been around for a few decades and is considered a standard process in the industry. So much so, that many consider it the official term describing data integration activities of all kinds. ETL collects large amounts of data from any number of sources, cleanses and converts it into the specific formats of the target systems, and then loads it to the target system for use by data consumers.
While ETL isn’t the same today as when it was first introduced in the 70s, it still suffers from several disadvantages. ETL is typically run in batch, taking hours to complete, and requires multiple staging areas, in order to process and transform huge amounts of data. It also demands that data engineering teams acquire proprietary skills to script the data pipeline flows and logic. In addition, ETL tools aren’t a great fit for today’s multi-cloud, high-velocity data integration needs, and can also be complicated and expensive to adjust.

As enterprises migrate their data to the cloud, ELT is gaining ground.
Emerging from the Clouds: Extract-Load-Transform (ELT)
The transition to the cloud has transformed how companies implement their data pipelines. Studies show that 65% of organizations choose data integration solutions based on cloud or hybrid cloud platforms. In order to overcome the heavy processing of the ETL data transformation phase, ELT leaves data transformation for the very end. ELT loads all the raw data extracted from the sources to the destination data store (typically a data lake), and then employs proprietary scripting to transform it on the lake, making transformation faster, and more cost-effective. This approach gives more control to the data scientists, who are now free to work with the raw data, without any dependence on IT.
But ELT has its drawbacks.
-
First, it’s relatively new, and considered a maturing technology.
-
Second, due to its dependence on data lakes, any companies that don’t work with lakes, won’t benefit fully from ELT.
-
Third, and more importantly, the raw data which was loaded to the data lake still needs to be cleaned, enriched and transformed. This time-consuming procedure is now done on a data lake, by a data scientist. Transforming the data on the lake is also very costly, since data lake vendors charge for storage and processing.
-
Fourth and final, data privacy and compliance may become compromised, since the raw data includes personal and sensitive information which is not masked.
Enter eETL (Entity-Based ETL)
To solve the above challenges, companies must shift their focus from moving large bulks of data in batch, to real-time data pipelining data via data products. This approach addresses the disadvantages of both ETL and ELT, for simpler and more secure data integration.
Entity-based ETL (eETL) executes the entire data “integration-preparation-delivery” cycle based on a data product, corresponding to a business entity (such as a customer, store, device, or order). The data for every data product instance (say, a customer) is organized and managed in a unique, encrypted Micro-Database™. Think of it as a logical abstraction layer (or data schema), unifying all its tables and data attributes, from all underlying data sources – regardless of the data format, technology, structure, or location.
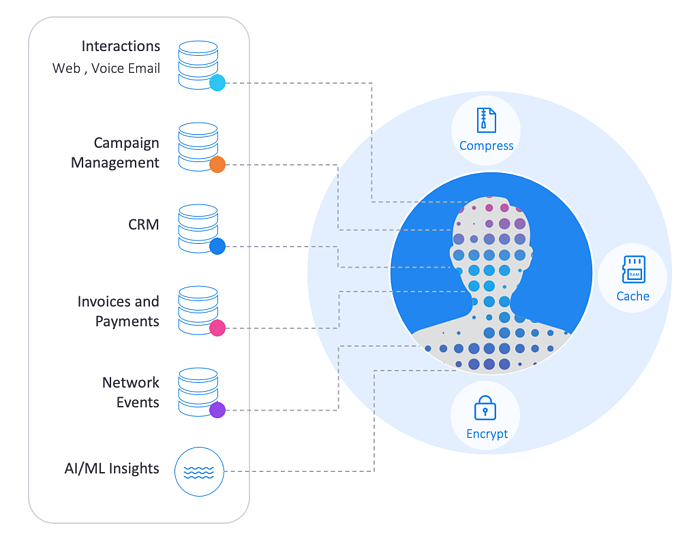
Entity-based ETL relies on patented Micro-Database technology to deliver sub-second response times.
eETL Advantages
A data pipeline of Micro-Databases delivers several important benefits:
-
Because data transformation is performed at the business entity level – with a 360-degree view of the entity – we can easily and quickly execute sophisticated data processing that would otherwise require cumbersome and compute-intensive querying, with joins across multiple tables of millions of records.
-
Data can be prepared, at any scale, within seconds.
-
Data can be integrated by a variety of methods, including push-and-pull, live streaming, or Change Data Capture (CDC), with all types of data sources supported.
-
Every part of the data preparation and delivery process can be performed in real time – including cleansing, formatting, enrichment, and data anonymization – allowing data engineers to apply analytics immediately on timely and trusted data. The time and money saved from this advantage alone, makes the entire entity-based approach worthwhile.
-
Not only is data pipelining agile and easy to maintain, but their iterative nature allows for full automation and productization. The data (including historical information, and copies of previous versions of the data) is available for business teams, across the organization.
-
Anonymizing the data on the fly complies with the latest data compliance regulations, potentially saving the company unwanted legal and PR trouble.
-
Because the data is transformed based on business entities, unnecessary storage and staging area costs are eliminated, so companies pay less for computing and processing.
Transitioning to eETL
Make the move from siloed data stores and tables (via ETL or ELT), to smart data pipelines based on a Data Product Platform (via eETL), to accelerate time to insights. With eETL, the same data integration that used to take weeks or months to complete, can now be done in minutes – one business entity at a time.

