





Data fabric is the modern data architecture of choice for enterprises, looking to democratize data access for operational and analytical use cases, at massive scale.
This article is intended for CDOs, CIOs, data engineers, data scientists, and their business counterparts – as a quick and easy guide to understanding data fabric vendors and their offerings.
Analyst firm Gartner defines data fabric as an important emerging trend that requires a combination of multiple data management technologies – such as data integration, data pipelining, data orchestration, data governance, and data catalog.
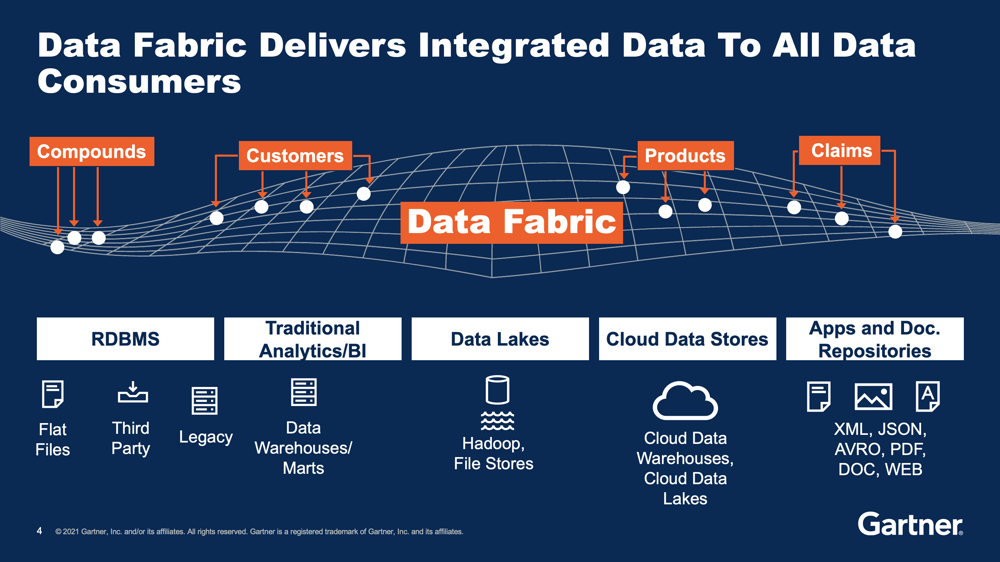
Gartner: “A data fabric stitches together integrated data from
many different sources and delivers it to various data consumers.”
The main goal of a data fabric is to deliver integrated and enriched data – at the right time, in the right way, and to the right data consumer – to support both operational and analytical use cases.

Successful data-driven enterprises map intended business outcomes to their data architecture and technology. This is why business and IT stakeholders need to know the reasons for implementing data fabric, and thoroughly understand its value proposition. Key drivers are described below.
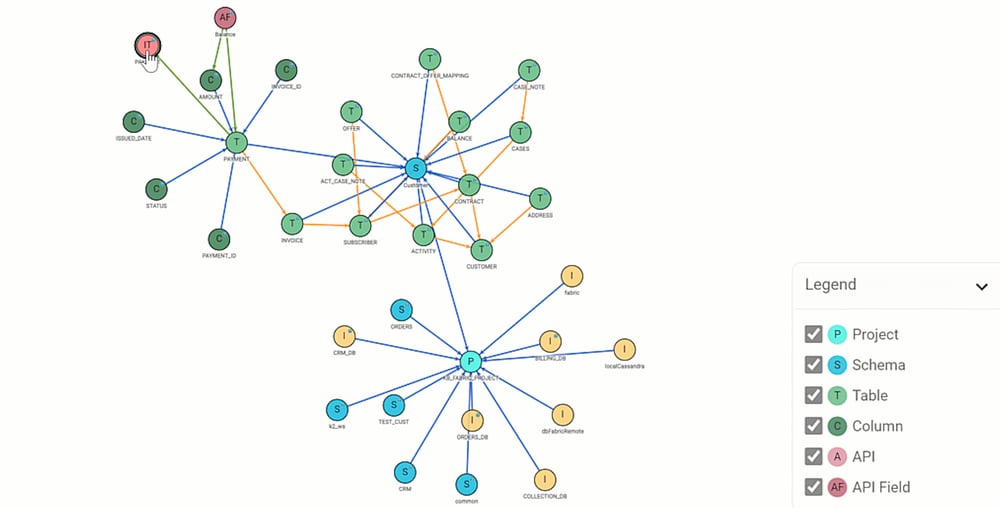
Knowledge graphs are important because most relationship insights are lost when using traditional data modeling and integration tools.
When researching data fabric vendors, look for a data fabric architecture that enables the following key capabilities:

The table below summarizes the strengths and concerns of the 5 top data fabric vendors.
| Strengths | Concerns | ||
| K2view |
|
|
|
Denodo
|
|
|
|
| Talend
|
|
|
|
Informatica
|
|
|
|
IBM Cloud Pak for Data
|
|
|
K2view stands out as the only platform capable of responding to data queries in real time, at massive scale, in support of both analytical and operational workloads.
At the core of K2view’s patented technology is the Micro-Database™, that unifies everything the enterprise knows about a particular business entity (such as a customer, product, location, credit card, etc.), including business transactions, cross-channel interactions, network data, and master data.
The Micro-Database integrates all data elements, regardless of source systems, technologies, and formats.
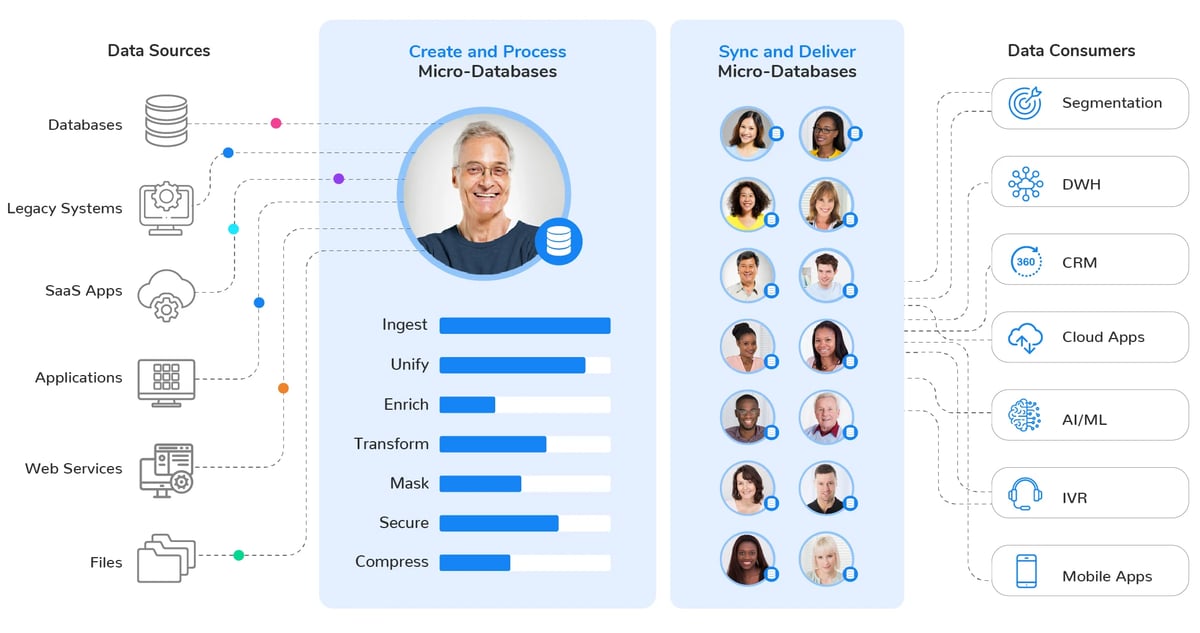
Everything a company knows about a customer is encapsulated in a Micro-Database.
At runtime, business entity (say, customer) data is integrated from underlying data sources, enriched, transformed, compressed (by as much as 90%), and stored in a Micro-Database – one per customer.
Each Micro-Database is secured with its own encryption key, meaning that data is protected at the customer record level. Data sync rules manage the frequency of data updates between the source systems and the Micro-Databases, and the architecture is distributed to support workloads of massive scale – in the cloud, on-premises, or in a hybrid architecture.
Key features