








Enterprise RAG:
Structured & unstructured data unified
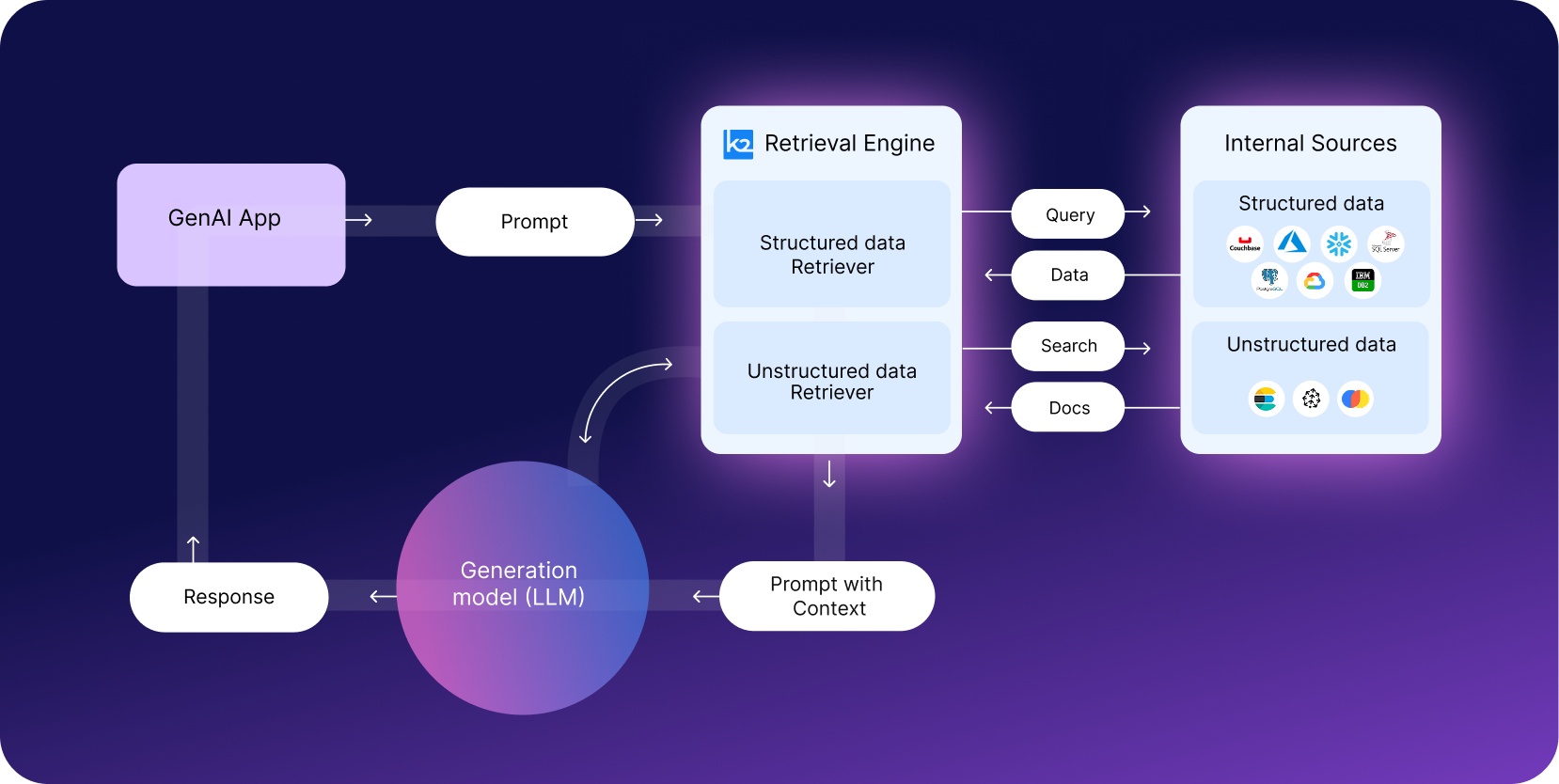
Retrieval-Augmented Generation (RAG) grounds GenAI in enterprise knowledge, but most implementations rely almost entirely on unstructured documents—policies, procedures, manuals. Useful, but this covers only a fraction of enterprise knowledge. Most business-critical data lives inside applications like ERP, CRM, and HCM.
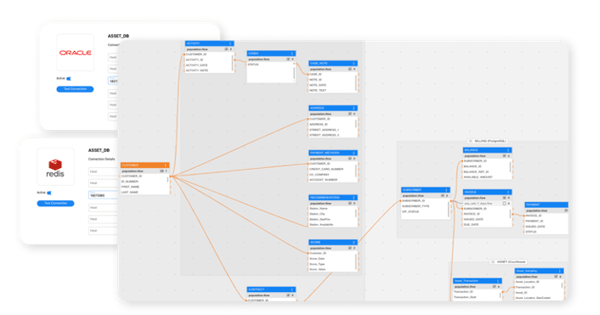
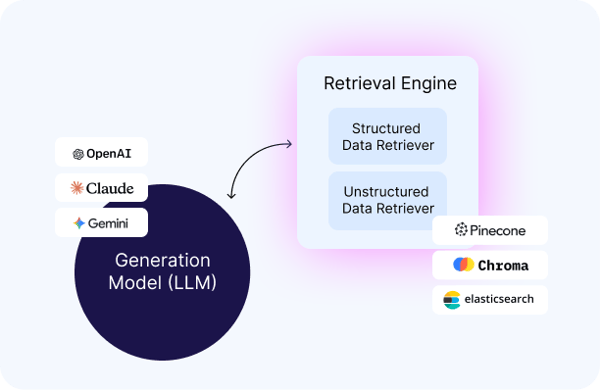
K2view extends RAG by unifying access to both documents and live application data in a single semantic layer. With real-time access, governance, and context, GenAI apps deliver responses that are accurate, secure, and context-rich.


Close the LLM knowledge gap
LLMs are trained on generic information. By grounding them in your business - customers, loans, suppliers, orders, employees - GenAI delivers accurate and relevant responses.

Tap the data that really matters
Most answers are found in operational systems like CRM, ERP, and HCM. With K2view, that data is instantly accessible to your GenAI apps.

Make AI Work in Real Time
Customers and employees expect answers in seconds, not minutes. With K2view, GenAI delivers fast, accurate responses at conversational speed, boosting satisfaction and trust.








Pelephone elevates customer experience with enterprise RAG
"For a GenAI-powered chatbot to be smart and effective, a GenAI-ready data infrastructure is required. That’s where K2view enters the picture."

"For a GenAI-powered chatbot to be smart and effective, a GenAI-ready data infrastructure is required. That’s where K2view enters the picture."
Cellcom combines GenAI and customer data to improve customer service
"K2view GenAi allows us to combine GenAI and customer data to transform customer service, and deliver real business value faster than ever."

"K2view GenAi allows us to combine GenAI and customer data to transform customer service, and deliver real business value faster than ever."
"K2view has a unique approach of integrating enterprise data with the LLM advantage"

EXPERIENCE OUR Synthetic Data Generation TOOL
Take the interactive product tour

Synthetic data generation
Create synthetic data for multiple systems based on user-defined business rules.

Synthetic data generation

product tour
This tour is best experienced on desktop
This product tour is best suited on desktop - you’re already signed in, if you like we’ll re-send you the link to the tour
product tour
This tour is best experienced on desktop
We’ll send you a link to your email for desktop experience of the product tour
product tour
Great, you’re signed up! Check your email
This product tour is best suited on desktop, we’ve sent you an email with a link to the product tour.
Enjoy and reach out to us for any questions!

Synthetic data subsetting
Provision a data subset from multiple systems using business parameters.

Synthetic data subsetting
product tour
This tour is best experienced on desktop
This product tour is best suited on desktop - you’re already signed in, if you like we’ll re-send you the link to the tour
product tour
This tour is best experienced on desktop
We’ll send you a link to your email for desktop experience of the product tour
product tour
Great, you’re signed up! Check your email
This product tour is best suited on desktop, we’ve sent you an email with a link to the product tour.
Enjoy and reach out to us for any questions!

Synthetic data masking
Anonymize production data in flight to ensure compliance with regulations.

Synthetic data masking
product tour
This tour is best experienced on desktop
This product tour is best suited on desktop - you’re already signed in, if you like we’ll re-send you the link to the tour
product tour
This tour is best experienced on desktop
We’ll send you a link to your email for desktop experience of the product tour
product tour
Great, you’re signed up! Check your email
This product tour is best suited on desktop, we’ve sent you an email with a link to the product tour.
Enjoy and reach out to us for any questions!



