





.png)



Table of contents
Searching for the right data integration tool? Look for the one that can support both offline big data analytics, and online operational intelligence.
Table of Contents
Analytics and Operations are Part of the Enterprise Fabric
Offline Big Data Analytics
Online Operational Intelligence
Wanted: A Data Integration Platform Optimized for Both Offline and Online Analytics
Data Product Platform: The Data Integration Platform for Both Analytics and Operations
Analytics and operations are part of the enterprise fabric
The common notion is that data architectures (e.g., data fabric and data mesh), are built for big data analytics. Much has been written about data platforms in support of trend analysis, predictive analytics, machine learning, and business intelligence – all of which are performed offline, by data scientists, to derive meaningful business insights.
However, there has been little coverage of the importance of such systems and architectures for operational use cases, like customer 360, data pipelining, cloud migration, data tokenization, legacy modernization, privacy compliance, and more. All depend on up-to-the-minute, accurate, and complete data. After all, you can’t rely on a fraud detection algorithm based on a user’s transaction data from the previous week.

Real-time decisioning relies on both big data analytics and operational intelligence
It makes no sense, for example, to have one data fabric solution for big data analytics, and another data fabric solution for operational intelligence. The ideal platform should be able to integrate and deliver data for both.
Offline Big Data Analytics
With the right set of data analytics tools, marketing analysts can use a data lake, for example, to define the optimal segment of customers to whom to target a specific promotional campaign. At the same time, data scientists can use that same data lake for feature engineering in order to build a churn propensity model.
An example of the latter might be a New York City bank that has determined that the chances of a Manhattan resident, at a specific income level, who owns an apartment, moving to a different bank are less than 1.4%. So, marketing would not target this customer segment with retention campaigns. And when a member of this segment calls customer service, they would not be flagged as a high-risk to churn. Makes sense, right? Not necessarily…
Online Operational Intelligence
Say the offline prediction models were run by the bank 12 hours ago, but 1 hour ago the bank portal went down just as John, an upwardly mobile, Manhattan apartment owner, was about to complete an important transaction. And for the past 30 minutes, he’s been trying to reach customer service unsuccessfully, hanging up each time after a 5-minute wait. Clearly, John is likely to be upset. Leveraging the understanding of the customer’s journey and behaviors as real-time inputs to the churn model, would deliver trusted, operational intelligence that would be incredibly useful to the service agent about to take John’s call.
Wanted: A Data Integration Platform Optimized for Offline
and Online Analytics
Like most animals, we humans have two eyes, serving to extend our peripheral vision, and enhance our depth perception. Both functions are essential to driving a car, for instance, where split-second decision-making is critical.
Using this analogy, imagine a data fabric within a platform that could maximize the field of vision, and the depth of understanding we have for each and every customer, on an individual basis. Such a data integration platform would not only provide enterprises with the complete, up-to-date data for offline big data analytics (“maximizing the vision”), but also be able to deliver actionable data in milliseconds, for online operational analytics (“maximizing the depth of vision”).
On the one hand, the data provisioned for offline analytics would be comprehensive and up to date, because it contains every possible thing there is to know about a customer or any other business entity (be it a vendor, loan, order, credit card, or virtually anything else important to the business). This kind of Customer 360 is critical because, in many cases, a customer’s data is fragmented and stored in separate systems, in different locations, making it extremely difficult to locate, collect, unify and cleanse.
On the other hand, serving all the data of a business entity into an analytical model in real time is crucial for the delivery of personalized actions and recommendations.
Data Product Platform: The Data Integration Platform for Analytics and Operations
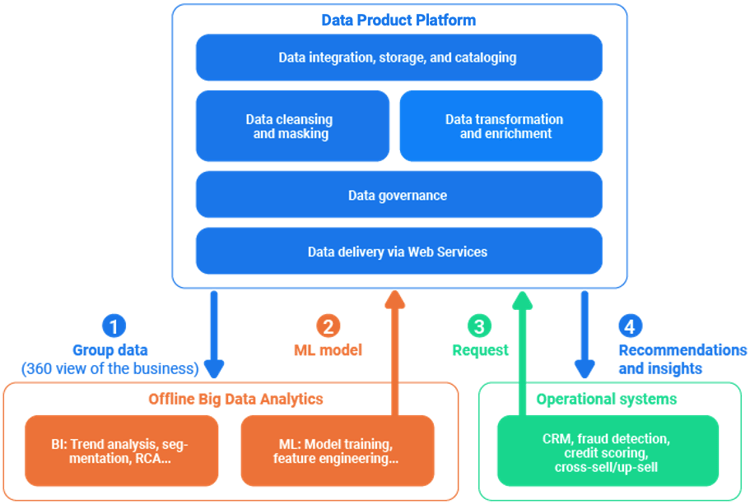
A Data Product Platform serves complete and trusted data for analytical and operational use cases.
-
It continually provisions high-quality group data, based on a 360 view of business entities – such as all customers in a certain segment, all company products, or all retail outlets – to big data stores, i.e., data lakes and data warehouses. Based on this data, data scientists create and refine Machine Learning (ML) models. Additionally, data analysts use Business Intelligence (BI) tools to perform trend analysis, customer segmentation and Root-Cause Analysis (RCA).
-
The refined ML model is deployed into the data platform / data fabric as a web service to be executed in real-time for an individual business entity (e.g., customer, product, location, etc.).
-
Upon request from an operational system, the data fabric executes the ML model in real time, feeding it the individual entity’s complete and current data.
-
The output of the ML model is returned instantly to the requesting application, and stored in the data fabric, as part of the entity, for subsequent analysis. The data fabric may also invoke real-time recommendation engines to deliver next-best-actions.
A Data Product Platform is optimized for both offline big data analytics, and online operational intelligence.

