




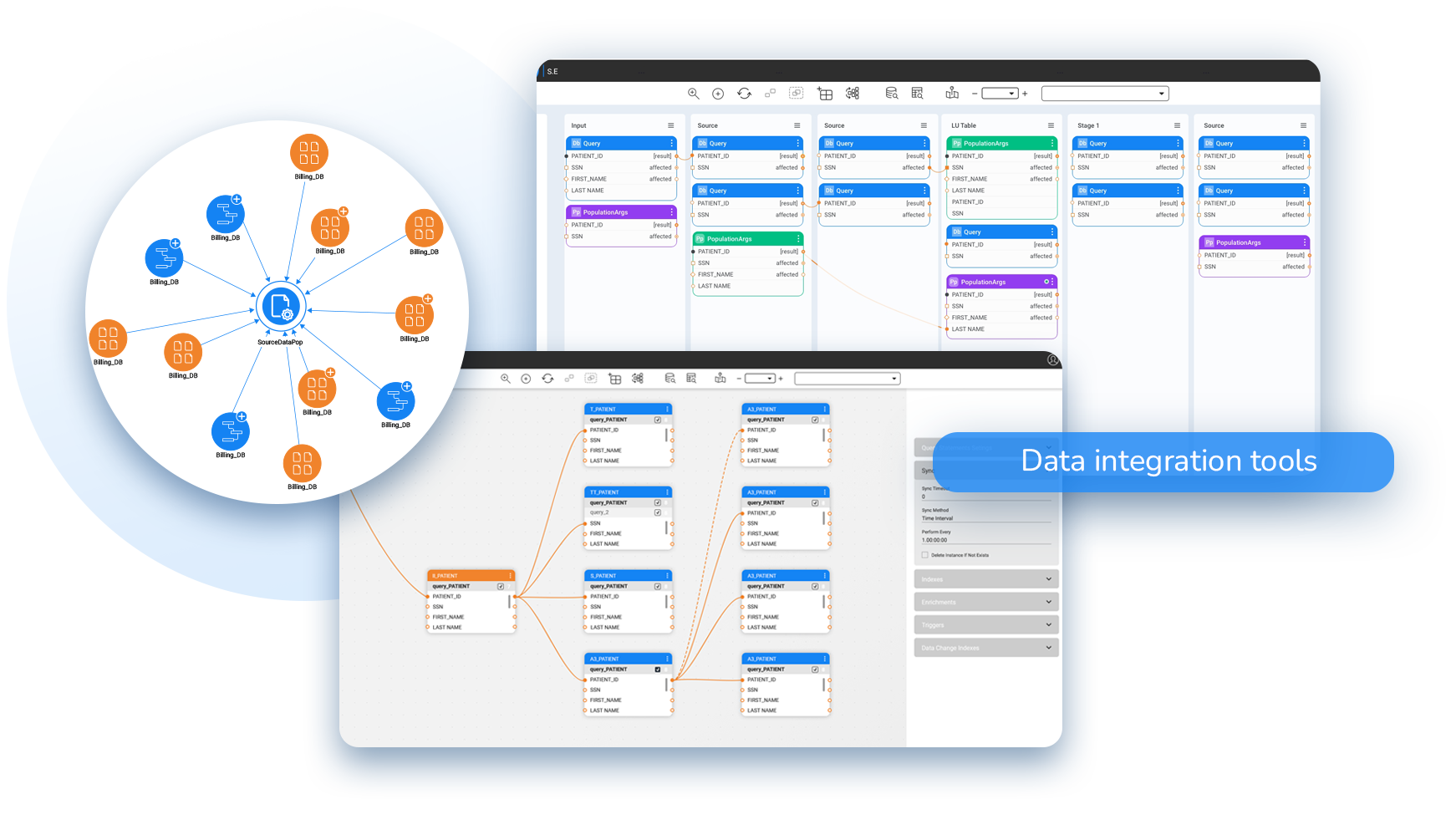
Data integration tools unify data from different sources into a single view. They make trusted data more accessible, and easier to consume, by:
According to analyst Gartner, data integration has traditionally been achieved by a combination of related tools, with different vendors offering different tools.
Although the primary market for data integration tools is ETL, there are overlapping submarkets of tools for data replication, and data federation (EII), as well as periphery markets of tools for data modeling, data quality, and adapters.
The problems associated with enterprise data integration are a direct result of this market confusion, with:
Enterprises have therefore been forced to amass a wide range of tools, from multiple vendors, to address all of their data integration needs.
As more and more organizations demand cross-company data integration, a new breed of highly focused vendors are stepping up to meet the market need with innovative technologies.
The market is now ripe for an all-in-one data integration platform, supporting all data integration styles, based on common design tooling, metadata, and runtime architecture.
In the Gartner Magic Quadrant for Data Integration Tools for 2022, the following 10 trends and drivers are listed:
The data integration market grew from 6.8% in 2020 to 11.8% in 2021, with a 5-year Compound Annual Growth Rate (CAGR) increasing from 7.0% to 8.5%. Cloud adoption is expanding, with the iPaaS market growing by 40.2% in 2021.
The top 5 vendors in the data integration market had a combined market share of 71% in 2017. By 2021, their collective market share dropped to 52%. One explanation for this phenomenon is that smaller vendors are disrupting the market with more focused, flexible offerings.
Vendors gaining market share are focusing on data virtualization, data replication, or cloud data integration. The 5 top vendors in this group collectively grew their revenue by 32% in 2021. In order for the larger vendors to combat their drop in market share, they must find the right tradeoff between all-encompassing platforms, and easily accessible point solutions.
Data fabric answers the immediate need for augmented data integration. By taking a data-as-a-product approach, data fabric architecture automates the design, integration and deployment of data products, resulting in faster, more automated data access and sharing.
Enterprises exploring data mesh need decentralized, domain-oriented delivery of data product datasets. Business teams are looking to data mesh architecture to:
– Access the data they need on their own, to meet their SLAs more effectively
– Design data products based on their own, unique subject matter expertise
– Benefit from semantic modeling, ontology creation, and knowledge graph support
Data integration tools need to be able to track and forecast all the costs associated with cloud integration workloads. Data teams should be able to connect the cost of running data integration workloads to business value, and allocate processing capacity accordingly. Data integration tools should therefore support financial governance, including price-performance calculations.
Data engineering translates data into usable forms by building and operationalizing a data pipeline across data and analytics platforms, making use of software engineering and infrastructure operations best practices. With more data infrastructure operating on the cloud, platform operations are becoming a core responsibility.
Data integration tools should support DataOps enablement. DataOps is focused on building collaborative workflows to make data delivery more predictable. Key features include the ability to:
– Deliver data pipelines through CI/CD
– Automate testing and validate code
– Integrate data integration tools with project management and version-control tooling
– Balance low-code capabilities
– Manage non-production environments in an agile way
9. Hybrid and inter-cloud data management support
Cloud architectures for data management (iPaaS), span hybrid, multi-cloud, and inter-cloud deployments. There are advantages and disadvantages in managing data across diverse and distributed environments. Data location affects:
– Application latency SLAs
– Data sovereignty
– Financial models
– High availability and disaster recovery strategies
– Performance
According to Gartner, almost half of all data management implementations use both on-prem and cloud environments. Support for hybrid data management and integration has therefore become critical – and today’s data integration tools are expected to dynamically construct, or reconstruct, integration infrastructure across a hybrid data management environment.
There’s a definite need for independent data integration tools that do not rely on the storage of data in a vendor repository or cloud ecosystem. Embedded data integration capabilities, delivered by vendors, could lead to potential lock-in issues, costs for leaving the service, and data silos. Although some native CSP data integration tools allow for two-way integration (to and from their own cloud data stores), any organization using more than one cloud service provider should acquire independent data integration tools.
Simply put, data integration routes data from source to target systems. Sometimes, the data is physically relocated to the target system (e.g., inflight integration of multiple data streams). At other times, source datasets are copied onto a big data store (e.g., consolidation of transactional data for analysis in a data lake).
System architects and software developers design programs that automate and manage data integration. While some types of data integration are fairly straightforward, like replicating data from one system to another, other types require the harmonization of different database schemas found in different source systems.
A common harmonization approach is to create a mediated schema that merges smaller, local source schemas into a larger, global schema – used to map the data elements back to the mediated schema. This can be done in a target system, such as a data lake, or in a virtualized environment – that delivers a unified view of the data from all its different systems, without physically loading it into a new data store.
The most common type of data integration is Extract, Transform and Load (ETL), where data is:
Extracted from its source systems,
Transformed (consolidated and filtered) for use in analytics workloads, and then
Loaded into a data warehouse.
ETL is a batch process that typically involves massive amounts of bulk data.
An alternative to ETL is the Extract, Load and Transform (ELT) type of data integration, in which the 2nd and 3rd steps of the ETL process are inverted. With ELT, raw data is:
Extracted from its source systems,
Loaded into a target system, and then
Transformed, as required, for individual analytics applications.
ELT is often favored by data scientists, who typically prepare data themselves, in order to access the data they need – for machine learning apps, predictive modeling, and other variations of advanced analytics – when they need it.
A good answer to the ETL vs ELT question is entity-based ETL (eETL), available on real-time data integration platforms, like Data Product Platform.
Other types of data integration include:
Change Data Capture (CDC), which syncs data updates between source and target systems in real time;
Data streaming, which integrates real-time data streams, and stores the newly combined datasets into databases, for operational and analytical use cases; and
Data replication, which copies data from system to another, for use in operational, backup and Disaster Recovery (DR) workloads.
Data virtualization, which gives business users and data analysts an integrated view of different datasets without having to rely on IT to load the data into a data warehouse, operational database, or any other target system.
Data virtualization tools are growing in popularity because they can augment existing analytics architectures for particular applications, or be used in conjunction with a data warehouse that may include a mix of different platforms.
The most common data integration use cases include:
Building data stores
Large enterprises use data integration to build data stores (data fabric vs data lake vs database) to conduct analysis, generate reports, operate queries, and provision data in a consistent manner.
Leveraging big data
Big data enterprises, like Amazon, Facebook, and Google, generate valuable business information from billions of users each day. Therefore data integration tools are a necessity for today’s businesses.
Generating operational intelligence
By delivering a unified view of data from multiple sources, data integration becomes the foundation for your operational intelligence platform. With more information at their disposal, analysts can make more accurate predictions, at any scale.
There are several benefits associated with data integration, including:
Better collaboration
While different business domains demand access to company data for shared and individual projects, IT demands a secure way to provide self-service data access. In the sense that domain experts are generating data that the rest of the company needs, data integration improves collaboration.
Fewer errors
To manually gather data, data teams have to know where to look, and what tools to use, to assure the completeness and accuracy of their datasets. Without data sync, reporting must be redone periodically to account for any changes. But with automatic updates, reports can be generated in real time, whenever they’re needed.
Greater efficiency
By automating unified views of company data, data teams no longer need to manually create connections whenever they have to build an application, or generate a report. The time saved on hand-coded data integration can be used more efficiently on analysis and execution, for greater productivity and competitiveness.
Cleaner, fresher data
Data integration tools can improve the value of a company’s data over time. With data integrated into a centralized repository, data teams can spot quality issues, and fix them quickly and easily – resulting in higher quality data, and, ultimately, better data analysis.
 The 5 most common challenges data teams face implementing data integration include:
The 5 most common challenges data teams face implementing data integration include:
Attention to detail
Before using their data integration tools, data teams need to be fully aware of:
– What data needs to be collected and analyzed
– Where that data is stored
– Who are the stakeholders (data engineers, data architects, data scientists, data consumers in business and IT)
– Which systems are using the data
– How is the analysis conducted
– When the data needs to be updated
– What reports have to be generated
Data integration with legacy systems
Data stored in legacy systems often lacks the times and dates of activities, which modern systems typically include.
Data integration with newer systems
Newer systems generate structured and unstructured data, in batch or real time, from a wide variety of sources, including the cloud, IoT machines, sensors, and video. Integrating this diverse array of information may be crucial for the business, but also extremely challenging for IT – in terms of accommodating for scale (massive volumes), performance (sub-second response times), and all the different formats and technologies out there today.
Data integration with external sources
Data extracted from external sources may not come with the same level of detail as internal sources, making it difficult to analyze with the same level of precision. Data sharing may also be an issue, due to contractual obligations.
Data compliance
Data teams would be well advised to adhere to data integration best practices, in terms of complying with the quality demands of the organization, and privacy laws enacted by the regulatory authorities.
When choosing your data integration tools, make sure they’re:
Cloud-compatible
As organizations migrate to hybrid cloud environments, make ensure your data integration tools can be run in single-cloud, multi-cloud, or hybrid-cloud environments.
Cost-effective
Make sure your data integration tools come with automatic updates, and parameter changes (increasing the volume of the data, or number of connectors), free of charge.
Easy to use
Today’s data integration tools should be as intuitive as possible, with a friendly GUI interface for simpler visualization of your data pipelines.
Equipped with lots of connectors
There are many applications and systems on the market today, so the more connectors your data integration tools have, the better off you’ll be (in terms of saving time and resources).
Open source
An open source architecture delivers greater flexibility, and helps avoid vendor lock-in.
 A data product approach to data integration processes and delivers data by business entities. When data integration tools are based on data products, they allow data engineers to build and manage reusable data pipelines, for both operational and analytical workloads.
A data product approach to data integration processes and delivers data by business entities. When data integration tools are based on data products, they allow data engineers to build and manage reusable data pipelines, for both operational and analytical workloads.
Entity-based tools auto-discover and model the data product schema, to define all the fields and tables for a specific business entity (e.g., customer, location, device, etc.) from all existing systems – regardless of the underlying technologies or formats.
A data product ingests the data for each instance of a business entity into its own individually encrypted Micro-Database™.
It then applies data masking tools and data orchestration tools – inflight – to make the individual entity's data accessible to any authorized data consumer, in any delivery style, with full compliance.
Data Product Platform integrates and delivers data from any data source (on-prem or cloud) to any data consumer, using any data delivery method: bulk ETL, data streaming, data virtualization, log-based data changes (CDC), message-based data integration, reverse ETL, and APIs.
The platform has a no-code data transformation tool for defining, testing, and debugging data logic and flows, designed for every need:
Basic, including data type conversions, numerical calculations, and string manipulations.
Intermediate, such as Find/Replace functionality, that accesses aggregatied data, data matching, reference files, and summarizations.
Advanced, like cleansing, combining (data and content sources), correlating, enriching, parsing, processing unstructured data, mining text, and validating data.
As opposed to conventional ETL vs ELT approaches, the platform makes use of an in-memory database to transform data in real time. Data transformation is applied at the level of the individual business entity, marked by the ability to respond in milliseconds and to create a massive-scale data pipeline.

According to the 2022 Gartner Magic Quadrant for Data Integration Tools report, Data Product Platform:
In this paper, we define data integration, discuss its trends and drivers, inner workings, types, use cases, benefits, challenges, and requirements – pretty much the same material covered by everybody else.
But we go beyond the standard descriptions, by introducing an entirely new concept: Integrating data via business entities (in the form of data products). This approach has tremendous advantages, especially in terms of data quality, scale, and speed.
Finally, we reveal a commercially available Data Product Platform, already in use by some of the world’s largest enterprises, where data integration is a core component. The platform debuted in the 2022 Gartner Magic Quadrant for Data Integration Tools report, with excellent reviews.