





A practical guide to data masking
What is data masking?
Last updated on January 26, 2026
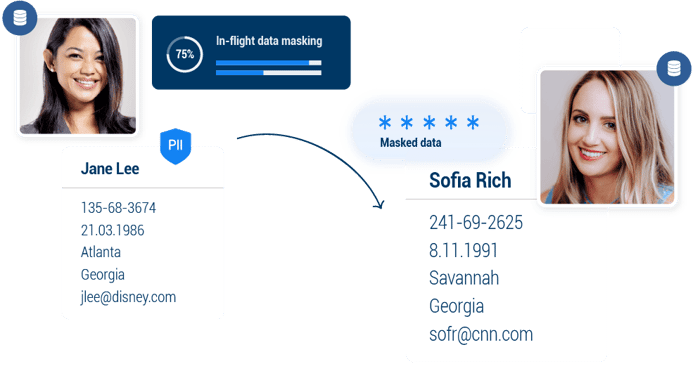

 Table of Contents
Table of Contents

01
What is data masking?
Data masking is a method for protecting personal or sensitive data that creates a version of the data that can’t be identified or reverse-engineered while retaining referential integrity and usability.
The most common types of data that need masking are:- Personally Identifiable Information (PII) such as names, passport, social security, and telephone numbers
- Protected Health Information (PHI) about an individual’s health status, care, or payment data
- Protected financial data, as mandated by the Payment Card Industry Data Security Standard (PCI-DSS) and the US Federal Trade Commission (FTC) acts and safeguards
- Test data, associated with the Software Development Life Cycle (SDLC)
Masked data is generally used in non-production environments – such as software development and testing, analytics, machine learning, and B2B data sharing – that don’t require the original production data.
Simply defined, data masking combines the processes and tools for making sensitive data unrecognizable to – yet functional for – authorized users.
The data masking process

The data masking process is an iterative lifecycle that can be broken down into 4 steps corresponding to 4 data masking phases – discovering the data, defining the masking rules, deploying the masking functionality, and auditing the entire process on an ongoing basis.
With the right data masking process in place, your data teams can:
- Discover and classify sensitive data
The data masking process begins by analyzing the metadata and data in your enterprise systems and classifying PII and sensitive data that require masking. Sensitive data discovery leverages rules-based and LLM-based techniques to identify the data to be masked. - Define data masking policies
Define the data masking policies for your use cases and set up the functionality to enforce them. Where dynamic data masking is required, define the Role-Based Access Controls (RBAC) that should be applied. Ensure that referential integrity and semantic consistency of the masked data are maintained. - Deploy
A best practice is to deploy data masking tools "close to the source", on premises, so that unmasked data is never transferred to the cloud. Proceed with the necessary security guardrails if data masking is performed in the cloud. - Audit and report for compliance
Generating exportable audit reports – for instance, including schema, table, and column name, as well as type, field, and probability of a match – is an ongoing part of the process.
03
Why data masking matters
Data masking solutions are important to enterprises because they enable them to:
- Adhere to privacy laws, like CPRA, GDPR, HIPAA, and DORA compliance, by reducing the risk of exposing personal or sensitive data, as one aspect of the total compliance picture.
- Protect data in lower environments from cyber-attacks, while preserving its usability and consistency.
- Reduce the risk of data sharing, e.g., in the case of cloud migrations, or when integrating with third-party apps.
Data masking is needed now more than ever, for masking sensitive data and addressing the following challenges:
1. Regulatory compliance
Highly regulated industries, like financial services and healthcare, already operate under strict privacy regulations. Besides adhering to regional standards, such as Europe’s GDPR, California’s CPRA, or Brazil’s LGPD, companies in these fields rely on PII data masking to comply with the Payment Card Industry Data Security Standard (PCI DSS), and the Health Insurance Portability and Accountability Act (HIPAA).
And companies aren't keeping up! According to our recent survey, 93% of companies admit that they're not fully compliant:

Test data compliance with data privacy regulations
Source: K2view 2025 State of Test Data Management report
The fact that only 7% of companies say they're fully compliant underscores a critical issue: the widespread presence of PII in test environments in spite of all the legislation to secure sensitive data.
Poor compliance also speaks to the challenges of managing enterprise data across diverse sources and systems, including modern databases such as NoSQL and data lakes and warehouses, as well as unstructured data and mixed environments (cloud and on-prem).
2. Insider threats
Many employees and third-party contractors access enterprise systems on a regular basis, for example for masking production data for testing or analytics purposes. Production systems are particularly vulnerable, because sensitive information is often used in development, testing, and other pre-production environments. With insider threats rising 47% since 2018, according to the Ponemon Institute report, protecting sensitive data costs companies an average of $200,000 per year.
3. External threats
In 2020, personal data was compromised in 58% of the data breaches, states a Verizon report. The study further indicates that in 72% of the cases, the victims were large enterprises. With the vast volume, variety and velocity of enterprise data, it is no wonder that breaches proliferate. Taking measures to protect sensitive data in non-production environments will significantly reduce the risk, one of many data masking examples.
4. Data governance
Your data masking tool should be secured with Role-Based Access Control (RBAC). While static data masking obscures a single dataset, dynamic data masking provides more granular controls. With dynamic data masking, permissions can be granted or denied at many different levels. Only those with the appropriate access rights can access the real data. Others will see only the parts that they are allowed to see. You should also be able to apply different masking policies to different users.


09
What are the top data masking tools for 2026?
1. K2view Data Masking
K2view Data Masking is a high-performance, enterprise-grade solution designed to mask data across structured and unstructured sources quickly and at scale.
| Criteria | Details |
|---|---|
| Best For | Enterprises with complex data architectures |
| Key Features | Entity-based masking, PII discovery, synthetic data generation |
| Pros | Fast, scalable, retains data relationships |
| Cons | Less known brand, setup complexity |
| User Rating | (4.5/5) |

2. IBM InfoSphere Optim Data Privacy
Built for non-production environments, IBM® InfoSphere® Optim Data Privacy provides realistic data masking for development and testing - ideal for regulated industries.
| Criteria | Details |
|---|---|
| Best For | Large enterprises managing dev/test data |
| Key Features | Variety of masking techniques, data subset support |
| Pros | Reliable masking, solid for test environments |
| Cons | Poor integration with data sources |
| User Rating | (4/5) |
3. Broadcom Test Data Manager
The Broadcom Test Data Manager helps you address data privacy and compliance issues as they relate compliance regulations and your corporate mandates. TDM combines masking with PII discovery and profiling. Works well for teams needing control over test data privacy and compliance.
| Criteria | Details |
|---|---|
| Best For | Enterprises focused on compliance |
| Key Features | PII discovery, profiling, subset/test data generation |
| Pros | Detailed data profiling, compliance-focused |
| Cons | Steep learning curve |
| User Rating | (4/5) |
4. Informatica Cloud Data Masking
Informatica Cloud Data Masking is known for its versatility and compatibility with many different data sources, ideal for organizations already using Informatica’s data integration tools.
| Criteria | Details |
|---|---|
| Best For | Enterprises with complex, multi-source data |
| Key Features | Persistent masking, cloud-native |
| Pros | Seamless with Informatica suite |
| Cons | Expensive, hard to master, limited support |
| User Rating | (3.5/5) |
5. Delphix DevOps Data Platform
Delphix DevOps Data Platform supports DevOps workflows with fast data provisioning and masking across development, testing, and analytics environments.
| Criteria | Details |
|---|---|
| Best For | DevOps and agile data teams |
| Key Features | Automated provisioning, multi-cloud masking |
| Pros | Dev/test automation, governance |
| Cons | Limited access controls for teams |
| User Rating | (3.5/5) |
6. OpenText Voltage SecureData Enterprise
The Voltage SecureData Enterprise platform protects any data over its entire lifecycle and helps customers solve complex data privacy challenges. Focuses on enterprise-grade format-preserving protection (FPE), combining encryption, tokenization, and masking for lifecycle-wide security.
| Criteria | Details |
|---|---|
| Best For | Enterprises with complex compliance needs |
| Key Features | FPE, tokenization, hashing, masking |
| Pros | Strong encryption, full-lifecycle security |
| Cons | Dated UI, poor docs, lacks unstructured data masking |
| User Rating | (3/5) |








