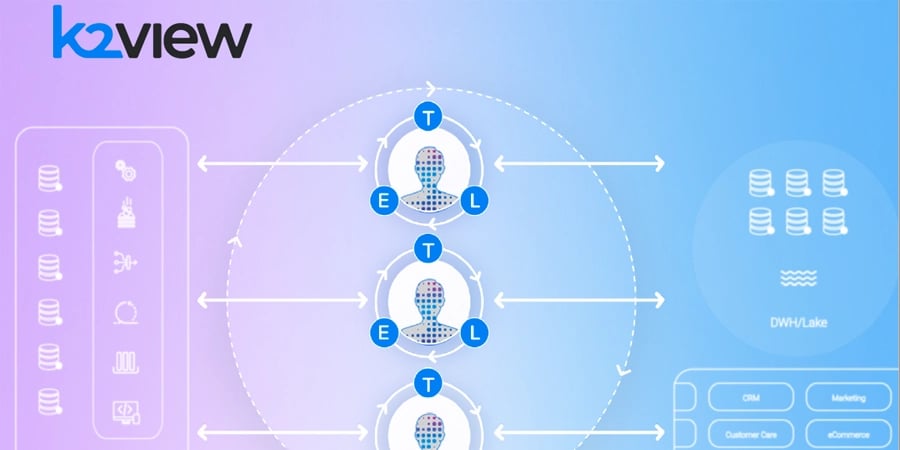
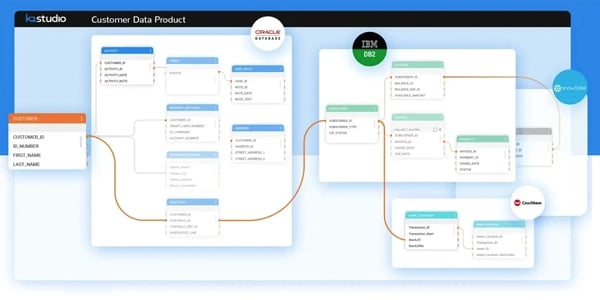
-
Platform

-
Solutions

-



🎉 K2view named a Visionary in Gartner’s latest Magic Quadrant for Data Integration