





Enterprises are migrating data at massive scale to keep up with the pace of business.
Data migration is the process of transferring data between computing environments, data formats, or storage systems. Data is moved from one place to another, or from one application to another, based on business and/or technology requirements.
Today’s enterprises migrate data for a variety of reasons, such as:
The most common example of data migration is data storage, where companies are migrating massive amounts of data from on-premise to cloud data stores, to increase performance and reduce costs.
Data migrations are complex, risky, expensive, and are often plagued by unexpected challenges. These challenges lead to shortcuts in testing and quality assurance, resulting in a turbulent post-migration experience for users of the new environment. To address these issues, data teams can proactively improve data quality, ensure regulatory compliance, and deliver on time, by relying on the right kind of technology to support their data migration efforts.
This guide first defines the WHY and WHAT of data migration, and then goes on to discuss its various strategies, tools, considerations, requirements, and a promising new technological approach.

The 3 main drivers for migrating data are:
Greater agility
Legacy applications are often the cause of obstacles and delays that negatively impact responsiveness. Enterprises need to be able to incrementally transform older systems in order to stay ahead of the game. Data migration enables the agility needed to sustain data-intensive enterprises.
Reduced costs
Legacy systems and technologies are often expensive to operate and maintain. Companies can save on both hardware and human resources, by moving data to the cloud, for example.
Increased collaboration
Breaking down legacy data silos enables business domains to gain cross-company visibility, and work better together.
Data migration starts with the identification, extraction, preparation, and transformation of data – and continues with its relocation from one data store to another. It concludes with validating the migrated data for completeness, and then decommissioning it from the legacy systems.
Data migration tools are used in any system consolidation, implementation, or upgrade. Ideally they offer automation in order to free up data teams from performing tedious tasks.
Project teams often underestimate the complexity inherent in data migration, and the time and effort needed for a successful conclusion. Midway through the project, they try to retroactively implement data migration best practices, but are often forced to take short cuts, and wind up delivering inadequate results.
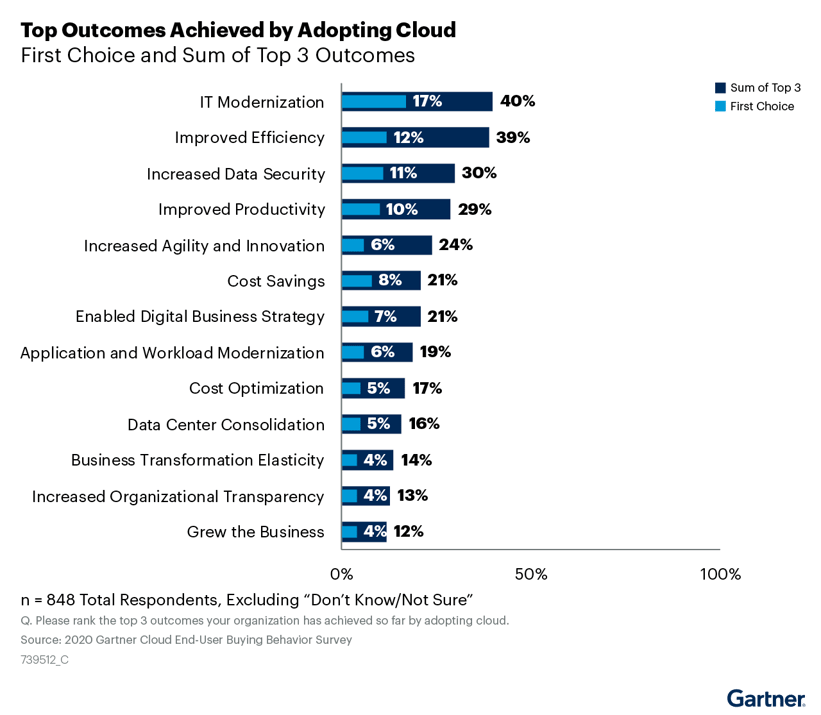
Data migration success factors
To ensure the success of data migration projects, data teams should apply specific techniques in 3 domains, as depicted below.
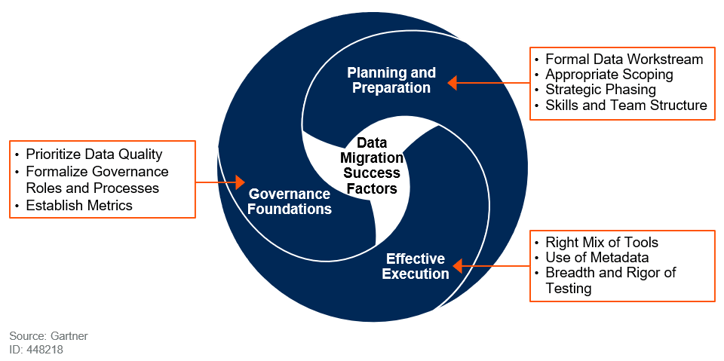
The 6 most commonly used types of data migration are listed below. Note that they’re fluid, in the sense that a specific use case may include aspects of both cloud and database migration, or involve storage and application migration concurrently.
There are 3 strategies to Data Migration, as detailed below.
Big bang data migration
Using a big bang strategy, enterprises transfer all their data, all at once, in a just few days (like a long weekend). During the migration, all systems are down and all apps are inaccessible to users. This is because the data is in motion, and being transformed to meet the specifications of the new infrastructure. The migration is commonly scheduled for legal holidays, when customers aren’t likely to be using the application.
Theoretically, a big bang allows an enterprise to complete its data migration over the shortest period of time, and avoid working across old and new systems at the same. It’s touted as being more cost-effective, simpler, and quicker – “bang”, and we’re done.
The disadvantages of this approach include the high risk of a failure that might abort the migration process, definitive downtime (that may have to be extended due to unforeseen circumstances), and the risk of affecting the business (e.g., customer loyalty when the apps can’t be reached).
A big bang strategy is better suited to small companies, and small amounts of data. It’s not recommended for business-critical enterprise applications that must always be accessible.
Phased data migration
A phased strategy, in contrast, migrates the data in predefined stages. For example, by customer segments: VIP customers, followed by residential customers, followed by enterprise customers...or by geography.
During implementation, the old and new systems operate in parallel, until the migration is complete. This may take several months. Operational processes must cope with data residing in 2 systems, and have the ability to refer to the right system at the right time This reduces the risk of downtime, or operational interruptions.
This approach is much less likely to experience any unexpected failures, and is associated with zero downtime.
The disadvantages of this approach are that it is more expensive, time-consuming, and complex due to the need to have two systems running at once.
Phased migrations are better suited to enterprises that have zero tolerance for downtime, and have enough technical expertise to address the challenges that may arise. Examples of key industries required to provide 24/7 service include finance, retail, healthcare, and telecom.
On-demand data migration
An on-demand strategy migrates data, as the name suggests, on demand. This approach is used to move small amounts of data from one point to another, when needed.
The disadvantage of this approach is in ensuring the data integrity of a “micro” data migration. On-demand data migrations are typically implemented in conjunction with phased data migrations.
Moving a massive dataset to the cloud, or anywhere else, is a highly complex undertaking that requires detailed coordination and planning to minimize disruptions.
Here are 10 data migration considerations:
Business impact
Is any data loss acceptable? If so, what kind, and how much? How would delays or unexpected challenges affect operations? How much time should a particular data migration take? For example, if a legacy system is being decommissioned, when will its license expire? What kind of data security is necessary throughout the migration process?
Cost
Is budget a priority? Using a cloud-based data migration tool saves on manpower and infrastructure costs, and frees up resources for other projects.
Data consumers
How will the data be used? For example, there may be different formatting and storage requirements for data used for regulatory compliance, compared to analytics. Who uses the data now, and who will use it in the future?
Data model
Does the data model have to change? Whether moving from an on-premise data lake to a cloud-based DWH, or from relational data to a mix of structured and unstructured data, cloud-based data migration tools tend to be more flexible than on-premise tools.
Data privacy and security
Is any of the data to be migrated of a sensitive nature? If so, it must comply with privacy regulations, that are often difficult to support during the migration process. Cloud-based tools are more likely to meet industry standards, while on-premise tools must rely on the security of the overall infrastructure.
Data quality
Does the source data need to be cleansed and enriched, or can it be loaded directly into the target? Which workflow is best at complying with data governance regulations, and improving data quality?
"Data migration projects often exceed their budget by 25% to 100% or more, due to a lack of proactive attention to data quality issues (a problem that persists post-migration)."
Data transformation
Does the migrated data need to be transformed (cleansed, enriched, merged, etc.)? Although all data migration tools can transform data, cloud-based tools are often the most flexible, and support most data types.
Data volume
How much data needs to be migrated? To migrate terabytes (TB) of data, a client-provided storage device is usually the simplest and least expensive way to go. However, to migrate petabytes (PB) of data, a migration device supplied by your cloud provider might be the best option. Alternatively, a cloud data ingestion tool, or an online data migration tool, could also be used.
Location
Will the data be migrated prem-to-prem (within the same environment), from prem to cloud, or from cloud to cloud?
Source/target environments
What subsets of data need to be moved? Will the same operating system be running in both old and new environments? Are there any data quality issues, and do they need to be addressed prior to migration? Will data formatting or database schemas need to change?
It’s extremely challenging and time-consuming for an enterprise to develop its own data migration solution. Especially when commercially-available tools are so much more efficient and cost-effective. To make the right choice, look at:
Connectivity
Does it only support currently used software and systems, or is it future-proof to account for evolving business requirements and use cases?
Scalability
What are its data volume limits, and is it possible that the organization’s data needs might exceed them in the future? Can it scale quickly?
Security
What security measures does it support? Is it responsive in adapting to, and complying with, new data privacy regulations, as they emerge?
Speed
How fast can the data be processed? Can it reach sub-second response times for data provisioning, to support operational workloads?
Transformation
Can it transform structured and unstructured data? Can it support data fabric, data mesh, and data hub architectures – on-prem and in the cloud?
Before embarking on a data migration program, be sure to:
Catalog your data
Use an automated data catalog to locate and access specific data quickly and easily.
Define your goals
Set your business goals, and select your data migration tool accordingly.
Mind your metadata
Augment your metadata with business context, curate it, and reveal data lineage and relationships between entities.
Govern your data
Enact data governance laws, that allow for no-code cleansing, enrichment, standardization, and data masking.
Migrating data is like moving offices. For example, take a company with many offices in a commercial building, moving to a new address.
In traditional data migration, data is moved one database table at a time. So in our example, only the computer equipment is moved, from each office in the old location, to each office in the new location.
The moving van then returns for the tables and chairs, and moves them in the same way. And it repeats this round trip process for the light fixtures – and, eventually, all the other office contents – until the move is complete.
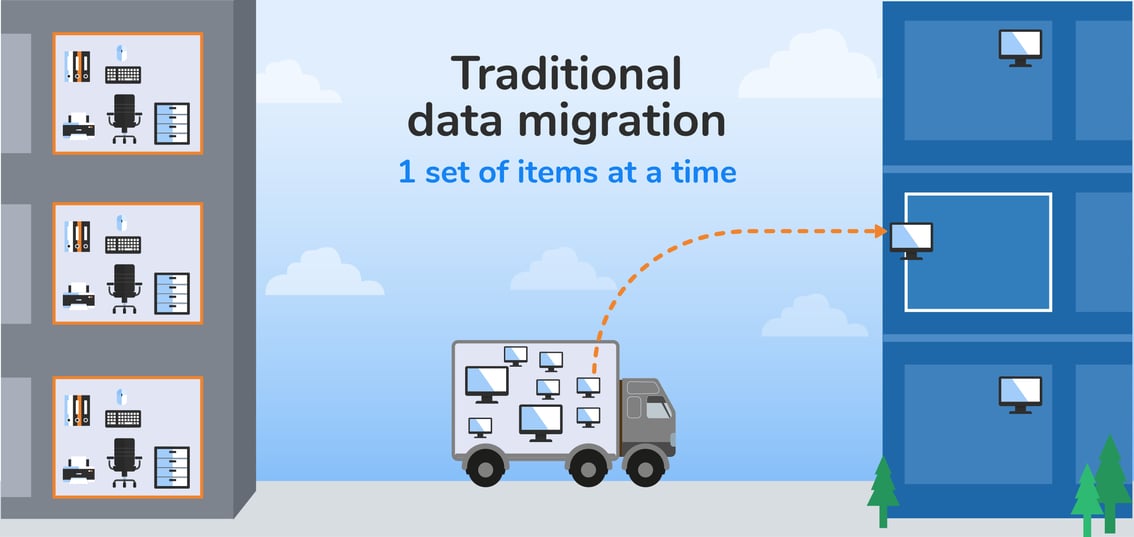
The traditional way to move data is table by table, field by field.
The problem with this approach is that it requires a business to shut down, typically during national holidays or long weekends.
Today, any outage, for any length of time, is unacceptable to enterprises expected to provide 24/7 access to its applications. Think consumers withdrawing cash from bank ATMs, filling prescriptions at drugstores, or texting via their cell phones. Shutting down such services is like saying goodbye to customers.
Data migration, based on business entities, is an elegant way to simplify the most complex migration projects. Going back to our moving van analogy, the contents of each office is moved in its entirety – computer equipment, tables, chairs, light fixtures, and everything else it needs to operate – at the same time.
Most of us have moved, from one home to another, at some point, so we know the drill. We don’t move only the electrical appliances in the house, separately, and then come back for the furniture, etc. We move everything in the house at once.
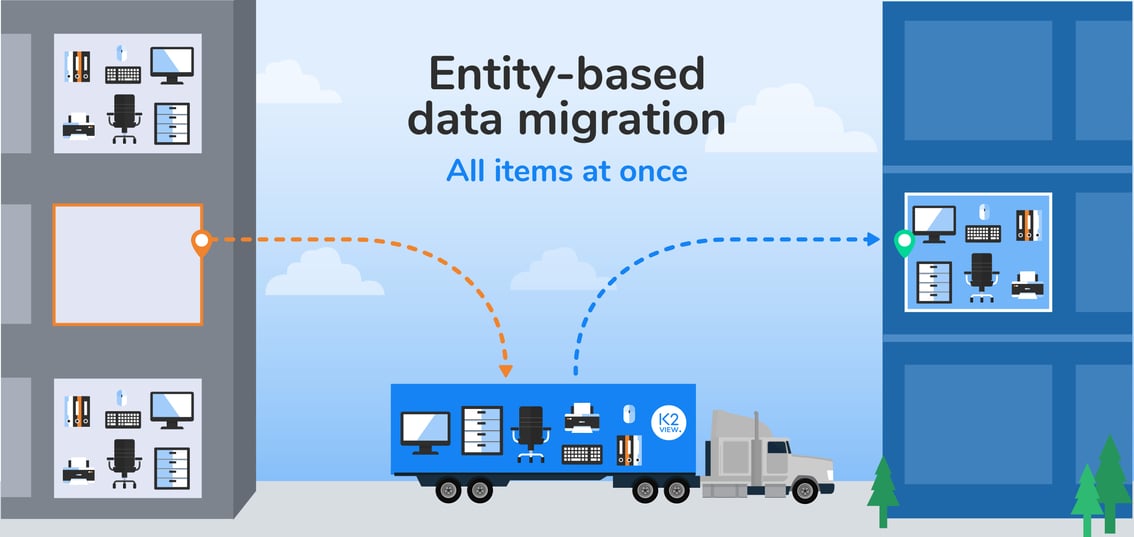
Entity-based data migration moves all the data associated with a
particular business entity (1 office) – together, at the same time.
The beauty of this process is that even during the split-second it takes for one office to be moved, every other office is open for business. That’s exactly what a business entity approach does for data migration. While one business entity (customer, order, or payment) is being moved – along with all its related datasets – all the others remain fully accessible. That’s the formula for operational continuity.
An entity-based approach enables the completion of complex enterprise data migration projects in weeks. The following is a summary of its advantages:
One migration platform, zero business disruption
Exceptional flexibility and time to value
Embedded validation
A data product refers to a reusable data asset, built to provide a trusted dataset for a particular purpose. It integrates and processes data from underlying source systems, assures that it’s compliant with privacy regulations, and delivers it instantly to authorized data consumers.
A data product generally corresponds to one or more business entities (customers, suppliers, devices, orders, etc.) and is made up of metadata and dataset instances.
From the moment it’s first deployed, a data product stores and manages each dataset instance in its own high-performance Micro-Database™, for enterprise-grade agility, resilience, and scale.
With entity-based data migration software, each business entity (say, customer) corresponds to a data product instance (say, John Doe), which can be reused for a variety of use cases, notably:
Data teams can set up K2view Data Migration tools quickly and easily with AI auto-discovering data sources, inferring entity relationships, generating rich metadata, and creating governed, reusable data products. Our entity-centric approach reduces the learning curve, accelerates ROI, and delivers complete, real-time, secure data for AI, analytics, and business operations.
