









Table of contents
With no predefined data model, conventional data masking tools can't process or analyze unstructured data. But deterministic entity-based data masking can.
Key takeaways
- Unstructured data masking protects sensitive information embedded in documents, emails, images, and chats – where there’s no fixed schema to target.
- It requires automated PII discovery and policy-driven masking techniques such as redaction, substitution, tokenization, encryption, and image blurring.
- Enterprise-grade results depend on deterministic masking that ensures referential integrity and maintaining contextual awareness for consistency across files and systems.
- Entity-based unstructured masking enables better regulatory compliance, safer AI and analytics, and more realistic testing without exposing sensitive data.
- K2view extends proven enterprise data masking to unstructured documents, presentation files, and templates while preserving structure and editability.
What is unstructured data masking?
Organizations increasingly rely on unstructured content such as presentation files, documents, PDFs, emails, and free-text files to capture institutional knowledge, share insights, and collaborate at scale. At the same time, these formats often contain sensitive, confidential, or proprietary information, making reuse risky, and manual redaction slow, error-prone, and costly.
Unstructured data masking is the process of identifying and obscuring sensitive information such as Personally Identifiable Information (PII) or Protected Health Information (PHI) within non-tabular formats like PDFs, emails, images, and chat logs. Unlike structured masking, which targets fixed database columns, unstructured masking identifies sensitive data hidden in natural language or visual media.
This article explains what unstructured data masking is, why it matters, where it’s used, and how enterprise-grade data masking – based on entity-centric data products – can be applied to real-world documents while preserving structure, layout, and business context.
Get Gartner’s data masking market guide free of charge.
Structured data vs unstructured data
There are 2 primary types of data:
1. Structured data
Structured data, which may also be categorized as quantitative data, is highly organized data that fits into a predefined data model. Structured Query Language (SQL) is the programming language used to manage structured data, and with an SQL agent, business users can easily input, search, and manipulate structured data. Structured data can also be easily deciphered by Machine Learning (ML) algorithms.
Common structured data use cases include:
-
-
CRM analytics tools, that reveal meaningful customer trends and behaviors
-
Online booking platforms, that record predefined reservation data, such as dates, prices, and destinations
-
Accounting software, that processes and records financial transactions
-
2. Unstructured data
Unstructured data, which is often categorized as qualitative data, cannot be processed or analyzed by conventional data tools. Since unstructured data doesn’t adhere to a predefined data model, it must either be managed in a non-relational (NoSQL) database, or in a data lake, to preserve it in raw form.
Sensitive unstructured data can be found within images, PDF contracts and agreements, driver licenses, XML documents, chats, and more. It is often stored on file shares, content management systems, as well as BLOBs or CLOBs within databases.
Typical use cases for unstructured data include:
-
-
Unstructured data mining, to monitor consumer behavior and purchasing patterns
-
Predictive data analytics, to better anticipate and adapt to shifts in the market
-
Customer service chatbots, to analyze text and route customer questions to the most relevant sources
-
Why unstructured data masking matters
With so much sensitive information floating around unstructured data files, effectively managing this data is crucial to both security and compliance efforts.
Unstructured data masking is integral to managing the following data governance needs:
1. Regulatory compliance
Complying with data privacy regulations is becoming more complex, while the penalties for noncompliance are becoming more severe. Highly regulated industries, such as financial services and healthcare, are already compelled to comply with regulations such as the Payment Card Industry Data Security Standard (PCI DSS), and the Health Insurance Portability and Accountability Act (HIPAA).
Following the enactment of GDPR and DORA European regulations, similar data protection laws are rapidly emerging the world over. Unstructured data masking supports compliance while still enabling operational and analytical workloads.
2. Data protection and security
In addition to the persistent threat of external hackers, insider threats also pose a significant risk. Insider breaches often occur due to broad access to enterprise systems by employees and third-party contractors. Production systems are especially vulnerable, because sensitive data is often used in development, testing, and other pre-production environments.
When PII, financial, medical, or any other type of sensitive information becomes anonymized data, it’s no longer a liability if accidentally exposed by business users, forgotten in testing environments, or hacked from the outside by malicious actors.
3. Data governance
Effective data governance tools are fundamental to maintaining data consistency and referential integrity across the organization. Controlling access to data is a primary component of data governance – and something that masking is very concerned with. While static data masking obscures a single dataset, dynamic data masking enables more granular levels of control as well as protecting data in transit. Only authorized users with appropriate permissions can access unmasked data. Learn more about static vs dynamic data masking.
Structured and unstructured data masking allows organizations to identify, monitor, and protect sensitive data, while maintaining semantic consistency and referential integrity across the enterprise.
Unstructured masking techniques, process, and use cases
Unstructured files are not just text strings. They include layout, styling, embedded objects, and metadata. A practical masking solution must protect sensitive data wherever it appears, including:
- Free text
- Templates, headers, and footers
- File names and naming conventions
- Repeated values across multiple documents
If masking flattens a presentation into images or converts files into screenshots, your ability to edit or reuse the file can be negatively impacted. Enterprise teams need masked outputs that can be reused and shared.
1. Techniques
Different unstructured formats and risk profiles call for different data masking techniques:
-
-
Redaction and black-lining permanently remove sensitive values by rendering them unreadable, such as black boxes over Social Security Numbers in a PDF.
-
Substitution with synthetic data replaces real values with realistic but fictional data, such as swapping a real name for a fake one, to preserve readability and context for testing and analytics.
-
Tokenization swaps sensitive elements with unique, non-sensitive tokens. This can be reversible via a secure vault if the original data must be retrieved later.
-
Encryption uses cryptographic algorithms to make text unreadable without a decryption key.
-
Blurring is used specifically for images, such as photo IDs, to obscure faces or sensitive text regions.
-
2. Process
Because unstructured data lacks a predefined schema, the process typically involves the following steps:
-
-
Discovery and extraction
Sensitive content must first be found. For images and scanned documents, Optical Character Recognition (OCR) can convert visual text into machine-readable text. For natural language, techniques like Natural Language Processing (NLP) and Named Entity Recognition (NER) help detect sensitive entities and patterns.
-
Classification
Discovered entities are categorized, for example address, credit card number, or medical condition. Classification helps organizations apply the right policy and technique based on sensitivity, regulation, and business need.
-
Masking application
Data masking methods are applied based on security policies. For example, a policy might require redaction for national identifiers, substitution for names and addresses in test documents, tokenization for customer IDs, and blurring for faces in photo IDs.
-
3. Use cases
Beyond security, unstructured masking is an enabler for safe and compliant data reuse across modern workflows. Common used cases include:
-
- Safe AI training
Scrubbing PII from datasets before using them in Large Language Models (LLMs) or Retrieval-Augmented Generation (RAG) pipelines to prevent leakage. - Regulatory compliance
Meeting PCI DSS, HIPAA, and GDPR data masking mandates. - Software testing
Creating realistic non-production environments using sanitized versions of real documents. - Collaborative research
Sharing medical histories or transcripts with third parties without exposing patient identities.
- Safe AI training
What are the benefits of entity-based unstructured data masking?
Entity-based data masking technology extends proven, enterprise-grade masking capabilities to unstructured data. It enables organizations to automatically discover and mask sensitive information in documents while preserving structure, layout, and business context.
1. Enterprise-ready solution
Entity-based data masking obscures unstructured data without flattening files, breaking layouts, or changing how documents are used. Since there are no screenshots, file conversions, broken formats, or manual reworks, the masked files can be used and shared immediately.
2. Automated PII discovery
-
-
Identifies PII and sensitive information using AI-assisted analysis combined with an enterprise data catalog.
-
Supports standard PII out of the box, including names, emails, phone numbers, addresses, IDs, and financial data.
-
Allows organizations to define custom classifications using business rules, patterns, and weights, such as project codes or proprietary identifiers.
-
Supports contextual discovery, including customer-specific knowledge, to detect sensitive data that generic tools often miss.
-
3. Inflight masking
-
-
Executes masking on the fly, without delegating to a language model.
-
Ensures consistent replacement of the same values across files, formats, and systems.
-
Preserves data format and realism, such as valid addresses, realistic dates, or compliant identifiers.
-
Applies conditional rules and exceptions, for example masking all emails except internal domains.
-
4. Format preservation
An entity approach masks sensitive data wherever it appears, including free text, templates, file names, and repeated values across documents. The result is a clean, anonymized document that looks and behaves like the original, without exposing sensitive details.
5. Context awareness
The business entity model allows masking decisions to account for real-world relationships and dependencies. When customer or entity context is available, it can improve discovery accuracy beyond pattern matching alone, maintain logical consistency across related data points, and ensure zero contradictions or downstream breakage.
6. Easy consumption and scalability
Unstructured data masking capabilities are exposed via APIs and can be embedded into existing workflows and interfaces.
-
-
Upload a file and receive a masked version in seconds
-
Scan folders or repositories such as SharePoint
-
Integrate into internal tools with minimal development effort
-
The masking process is fully transparent to consumers of the masked documents.
7. Security by design
-
-
Files are processed in-memory as part of the masking flow
-
No persistent storage is required unless explicitly configured
-
All processing occurs in vitro, within the customer’s environment
-
Which data masking tools specialize in unstructured data?
The following table shows the top 5 data masking vendors offering solutions for unstructured data files:
|
Tool |
Description |
|
Entity-based masking across structured and unstructured sources, deterministically maintains consistency across systems by tying masking to business entities (e.g., customers) and applying masking dynamically at scale. It embeds automated PII discovery and masking capabilities in its broader set of enterprise data masking tools. |
|
|
2. IRI DarkShield |
Discovery and remediation for dark data in files and folders, with multi-threaded discovery, extraction, redaction, and reporting across many semi-structured and unstructured formats and locations (network and cloud). It supports running jobs via GUI as well as APIs and OpenAPI-based automation, and includes audit-style reporting. |
|
3. Tonic |
Realistic synthetic data for engineering teams, with product modules that cover structured test data generation and free-text redaction and synthesis for unstructured content. Often used for creating test data, Tonic handles unstructured text via redaction and synthesis workflows. |
|
4. Protegrity |
Data-layer protection methods such as tokenization and encryption, positioned around field-level protection across multiple environments. It emphasizes applying protection methods (for example tokenization, or data anonymization vs encryption) close to where data is stored or processed to balance usability, compliance, and analytics requirements. |
|
5. BigID |
Discovery, classification, and action-oriented remediation for unstructured data at scale, typically used to detect sensitive data lives across documents, email, and cloud storage, and remediate any issues. BigID deals with discovering and contextualizing data to enable masking, encryption, tokenization, deletion, and other remediation workflows. |
How to implement unstructured data masking quickly and easily
Unlike conventional data masking solutions, entity-based deterministic data masking delivers all of the data related to a specific customer, order, payment, or device – to authorized data consumers – inflight and at massive scale.
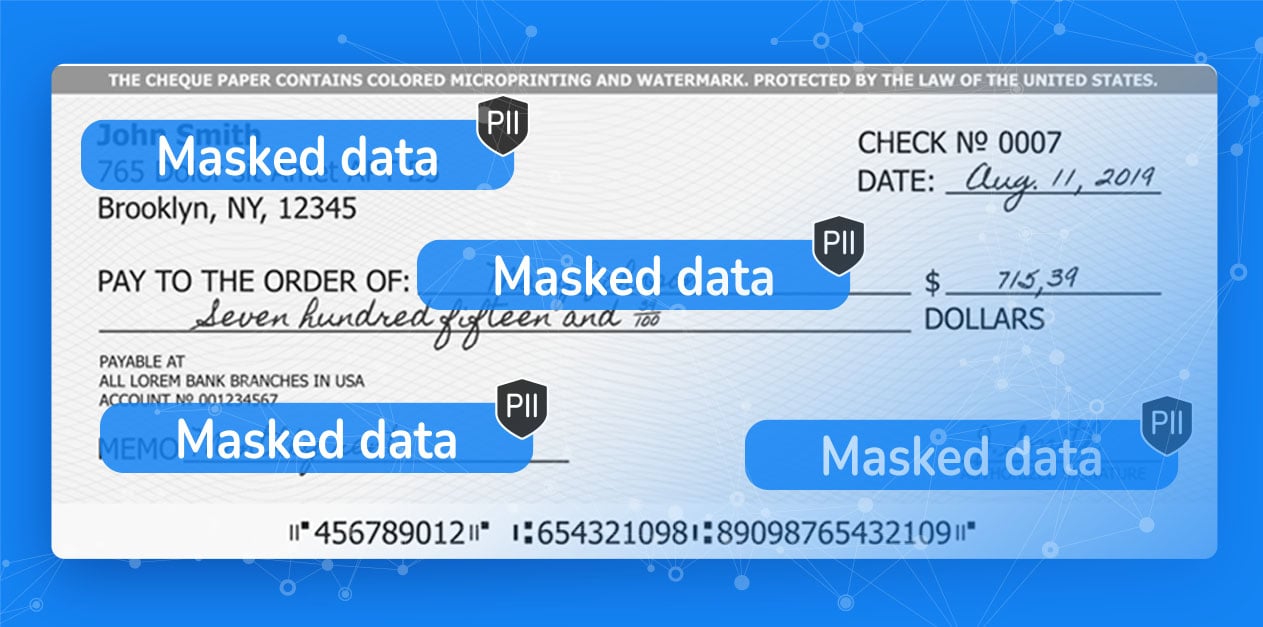
Entity-based data masking obscures unstructured data, like images, PDFs, text files, and more. For example, it replaces real photo IDs with fake ones, performs sensitive data discovery, PII masking, and synthetic data generation (of digitized receipts, checks, contracts, etc.) for testing and analytics purposes.
A business entity approach to data masking deterministically ensures referential integrity and semantic consistency across both structured and unstructured datasets.
And, when a single platform automatically discovers and masks sensitive data across all systems, data governance, security, and compliance are far more manageable.
Discover why the world's largest enterprises choose K2view
entity-based data masking tools for unstructured data masking.

