









Table of contents
For many companies, data masking is the best way to ensure data security and compliance, but which techniques are best for your business?
Table of Contents
What are Data Masking Techniques?
What Data Should be Masked?
The 6 Most Common Data Masking Techniques
Top Data Masking Challenges
The Most Effective Technique: Entity-Based Data Masking
What are Data Masking Techniques?
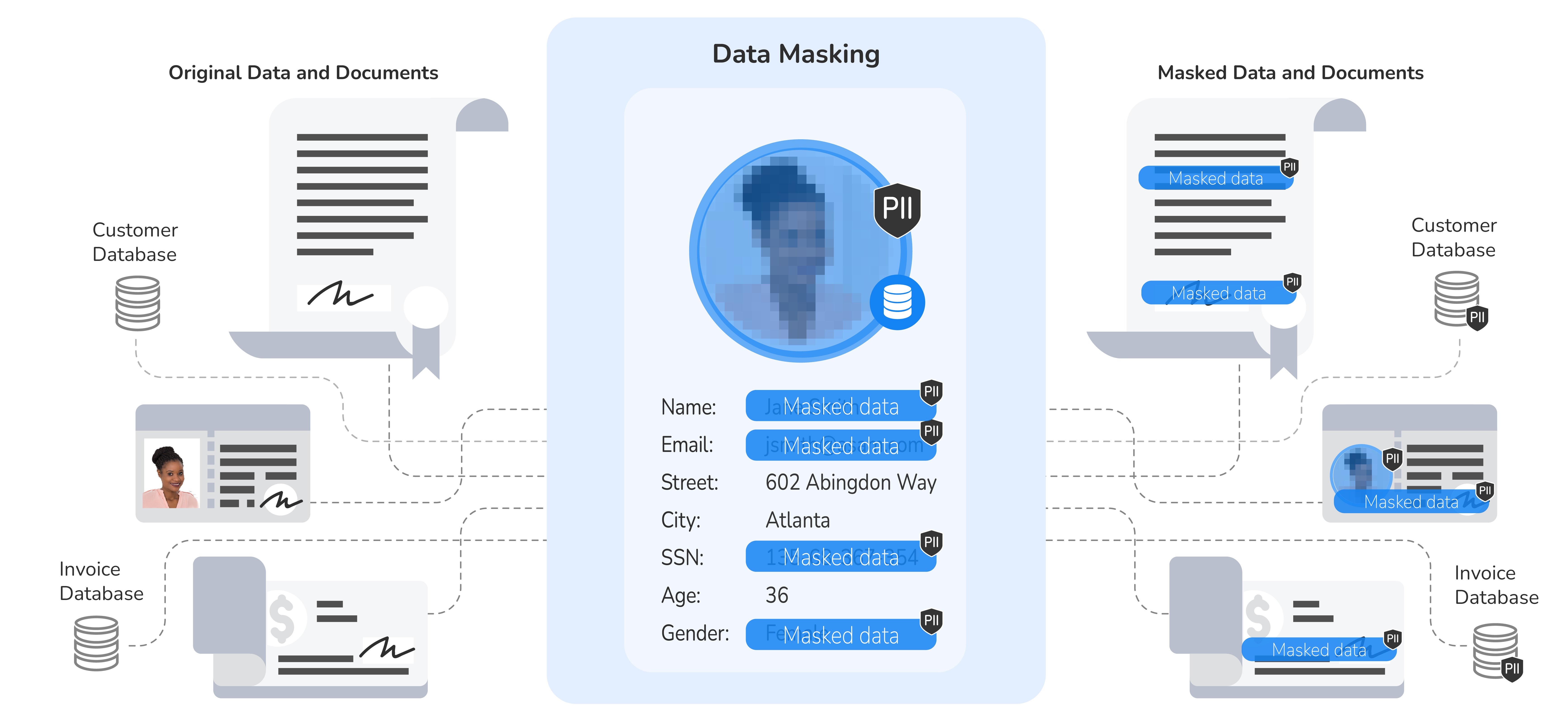
Data masking techniques are methods of data obfuscation that create a version of data that is structurally similar to the original data but hides sensitive and Personally Identifiable Information (PII) while maintaining referential integrity.. Data masking techniques include data anonymization, pseudonymization, redaction and scrambling, among others.
Data masking is employed to ensure compliance with data privacy regulations, such as GDPR and CPRA, and serve use cases such as software testing, data analytics, B2B data sharing, and user training.
Keep reading to learn more about the common data masking techniques, top challenges, and the benefits of entity-based data masking technology.
Get Gartner’s market guide for data masking free of charge.
What Data Should be Masked?
Different industries and sectors are required to comply with different data privacy regulations. Therefore, every company has different priorities when evaluating data masking solutions, depending on the type of sensitive data they need to protect, and the regions within which it operates.
-
Personally Identifiable Information (PII)
Just as it sounds, PII is data like full name, email address, or passport and social security numbers, that can be used to uniquely identify an individual. -
Protected Health Information (PHI)
PHI refers to medical and insurance-related data, collected by healthcare service providers, including demographic information, test and laboratory results, medical conditions, and prior claims. -
Payment Card Information (PCI)
PCI, as it relates to the Payment Card Industry Data Security Standard (PCI DSS), refers to credit and debit cardholder data. According to the standard, companies that process or accept credit and debit card payments must secure this data.
To discover such sensitive information, data teams also rely on unstructured data masking (of images, PDFs of contracts and agreements, driver's licenses, XML, and more). For example, if you store medical files as PDFs, you can ensure all sensitive information is adequately protected.
7 Common Data Masking Techniques
-
Data anonymization
Data anonymization is a method of information sanitization that involves substituting the sensitive data in a dataset with fake, but realistic data. It's an irreversible technique that minimizes the risk of a data privacy breach, while maintaining the structure and consistency of the data to support software testing and analytics. -
Pseudonymization
Pseudonymization swaps sensitive information, such as a name or driver's license number, with a fictional alias or random figures, while storing the original values in a secured manner. Unlike data anonymization, pseudonymization is a reversible process that can also be applied to unstructured data (like a photocopy of a passport). -
Encrypted lookup substitution
Another technique for masking production data involves the creation of a lookup table that provides realistic alternative values to sensitive data. These tables must be encrypted to prevent a breach. -
Redaction
Redaction is a data masking technique that replaces a field that contains sensitive data, either fully or partially, with generic values or constants. For example, a social security number may be redacted by replacing the first 5 digits with "*****", while leaving the last 4 digits intact. This technique is useful when the sensitive data itself isn’t necessary for QA or development, or when dynamic data masking is employed. -
Shuffling
Instead of substituting data with generic values, shuffling is a technique that randomly inserts other masked data. For example, instead of replacing employee names with fake ones, it scrambles all of the real names in a dataset, across multiple records. -
Data aging
If data includes confidential dates, you can apply date transformations to conceal the true date. For example, you can set back the dates by a random number of days to hide the original date. Special care is required to ensure that the new date fields are consistent with the rest of the data (e.g., that an activation date is not earlier than a creation date, or that a "to-date" is not earlier than a "from-date"). -
Nulling out
This data masking technique protects sensitive data by simply applying a null value to a data column, so unauthorized users won’t be able to see it.
Top Data Masking Challenges
-
Format preservation
In most use cases, the data masking technique must preserve the format of the original data. So your metadata must be accurately classified to preserve the formats of ID numbers, telephone numbers, email addresses, etc. -
Referential integrity
Referential integrity refers to masking each sensitive data value consistently across all databases. For example, the masked value of a specific social security number will be identical across all databases in which it appears. Maintaining referential integrity assures the uninterrupted operation of enterprise systems in lower environments where the sensitive data is masked. -
Semantic integrity
Semantic integrity refers to masking the data in a way that preserves its meaning within the context of the data. For example, if you were to mask the date of birth of a customer from an original value of 76 to 35, your data masking technique would also need to change the corresponding value in the "Senior Citizen" field accordingly. -
Gender preservation
When obfuscating names that need to remain private, your data masking methods must have the ability to decipher the correct gender associated with the name. If names are changed randomly, the gender distribution in a table will be altered. -
Data uniqueness
If the sensitive data in a dataset is unique, as in the case of a social security number, your data masking solution should apply unique values to each data element. This technique should also have collision-avoidance functionality built in.
Entity-Based Data Masking Supports All Techniques
Entity-based masking resolves the most common data masking challenges, while enabling data masking best practices. This technique masks all of the sensitive data related to a specific business entity, as a unit – such as customer, payment, order, or loan – and makes it accessible to data consumers based on role-based access controls.
Unlike other data protection methods that persist sensitive data in a staging environment, the entity-based data masking technique ingests, masks, and delivers masked data inflight.
Here's how it works:
- The data for a specific business entity (say, a customer) is ingested from all relevant sources.
- The sensitive data is masked while ensuring referential integrity.
- The resultant compliant dataset is then safely delivered to downstream systems.
With business entities, it’s easy to protect data – at rest and in transit – for software testing, data analytics, and training environments. The entity-based approach supports static and dynamic data masking, structured and unstructured data masking, test data masking, and more. Images, PDFs, text, and XML files that might contain sensitive data are protected, while analytical and operational workloads can continue running without interference.
For companies that require a range of data masking techniques, and want to avoid the vulnerabilities associated with conventional methods, a business entity approach is the way to go.
Discover K2view entity-based data masking tools.

