









Table of contents
Dynamic data masking is a data masking technique that limits the exposure of personal or sensitive data by anonymizing it for all non-authorized users..
Table of Contents
What is Dynamic Data Masking?
Benefits of Dynamic Data Masking
Dynamic Data Masking vs On-the-Fly Data Masking
Dynamic Data Masking vs Static Data Masking
3 Dynamic Data Masking Musts
Cover All the Bases with Business Entities
What is Dynamic Data Masking?
Dynamic data masking is a data masking (aka data anonymization) technique that limits sensitive data exposure by masking it for all non-authorized users.
Dynamic data masking allows data teams to specify the type and extent of sensitive data non-authorized users can access. It can be configured on designated databases to conceal PII in the result sets of queries, without making any physical changes to the original production data. This can significantly simplify security design, and coding in the application layer, with minimal impact.
Data masking tools that enable a dynamic approach are invaluable to enterprises, because they minimize the risk of a data breach, and noncompliance, while providing developers adequate access to databases.
Read on to learn more about dynamic data masking, how it stacks up against other data masking techniques, and how a data product approach covers all the bases.
Benefits of Dynamic Data Masking
-
Reduced security and non-compliance risk
Dynamic data masking helps mitigate risk of a breach and noncompliance with data privacy laws, by automatically delivering anonymized data to users without the right privileges. -
Easy configuration
Dynamic data masking provides enterprises with the flexibility to define which data should be masked, and how it should be masked (partially or fully), based on roles and permissions. -
Minimal impact
Data masking software provides enterprises with the flexibility to define which data should be masked, and how it should be masked (partially or fully), based on roles and permissions. -
Increased speed and agility
Masking data in real-time while keeping data inside databases intact helps speed up the pace of development and increase business agility.
Dynamic Data Masking vs On-the-Fly Data Masking
If you’ve read about dynamic data masking before, you’ve most likely heard the term “on-the-fly” data masking. Although sometimes used interchangeably, these terms refer to different processes.
Dynamic data masking happens in real-time, on-demand, and presents masked data within query results. Therefore, there’s no need for a second data source to store the masked data.
On-the-fly masking is used without a staging environment, when there’s not enough space, or when data is moved from one source location to another. On-the-fly data masking techniques rely on Extract-Transform-Load (ETL) methodology to move data, from where it resides, to the target environment. Note that only the target data is masked, while the source data remains unchanged.
Although the terms sound similar, it’s helpful to know that in-flight data masking and dynamic masking refer to the same process, unlike on-the-fly data masking.
Dynamic Data Masking vs Static Data Masking
Now let’s compare dynamic data masking to static data masking.
Dynamic data masking refers to data that's concealed after it's retrieved from a database, but prior to being presented to an application. In other words, the data is dynamically masked “in-flight.”
A common use case for dynamic, or in-flight, data masking is obscuring PII exposed to unauthorized users.
As the name implies, static data masking occurs when data is at rest, typically in the context of batch processes. In this case, data masking occurs in the database where it is stored. The masking is permanent, with no copy of the original, unmasked data available for presentation.
A typical use case for static data masking is the cloning of production data into non-production systems for software development or testing. In those cases, test data management teams only require realistic data – there is no reason to expose personal or confidential data.
3 Dynamic Data Masking Musts
Before choosing among data masking vendors, make sure your selection has the following capabilities:
-
Retention of relational integrity and semantic consistency
Relational integrity means that your data is represented in the same way across your databases. Semantic consistency contextualizes your data to ensure it "makes sense". For example, a cell phone user can't be a minor and also married. To achieve these goals, your data masking software must apply the same algorithms to every type of data originating from a certain business system. Integrity and consistency enable better cybersecurity, while also assuring that the masked data remains functional for analytics. -
Granular data masking
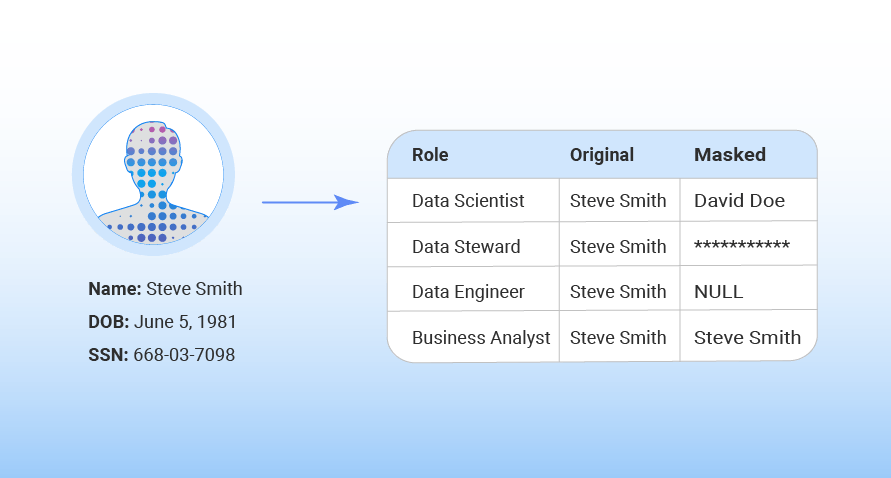
For dynamic data masking to be effective, it needs to be able to expose data on a “need-to-know” basis. Therefore, it’s important that your data masking tool can mask data at the table or column level, according to roles and permissions. -
Unstructured data masking
Sensitive data commonly resides within unstructured data, such as images, PDF files, drivers licenses, XML docs, chats, and more. Unless your data masking solution is capable of unstructured data masking, you’ll be leaving a gaping hole in your data privacy management strategy.
Cover All the Bases with Business Entities
The easiest way to cover all of the “musts” listed above, unlock the key benefits of dynamic data masking, and minimize risk of a breach and noncompliance, is via entity-based data masking technology.
A business entity approach delivers all of the data related to a specific customer, payment, order, or device – to authorized data consumers. Unlike many other data protection solutions, which centralize sensitive information in a vault or repository, entity-based dynamic data masking persists and manages every instance of particular entity data in its own individual encrypted Micro-Database™.
With entity-based dynamic data masking, you can mask structured and unstructured data dynamically and statically, while preserving referential integrity and semantic consistency. It integrates with any data source, masks any type of data, automatically discovers and masks PII at scale, and de-identifies it dynamically according to predefined roles and permissions.

