









Table of contents
For your data preparation process, use a data fabric architecture on a Data Product Platform, instead of an assortment of standalone tools.
Table of Contents
Data Preparation Process Flow
Data Preparation Tools and Trends
Data Fabrics Enter the Fray
The Entity-Based Data Fabric – a New Approach to the Data Preparation Process
Data Fabric: The Future of Data Preparation
According to Gartner, by 2024, an augmented data pipeline, supported by a data catalog, and a range of data virtualization, data unification, and data quality tools, will converge into a consolidated data fabric used for the majority of new analytics/data science projects.
In determining your company’s data preparation process, a data fabric run on an all-in-one Data Product Platform, offers you more than today’s standalone tools, since the same clean and trusted data can also be delivered to your operational applications. It also operationalizes the process, by having data engineers build a data pipeline, and then package the data flows for reuse by other departments.
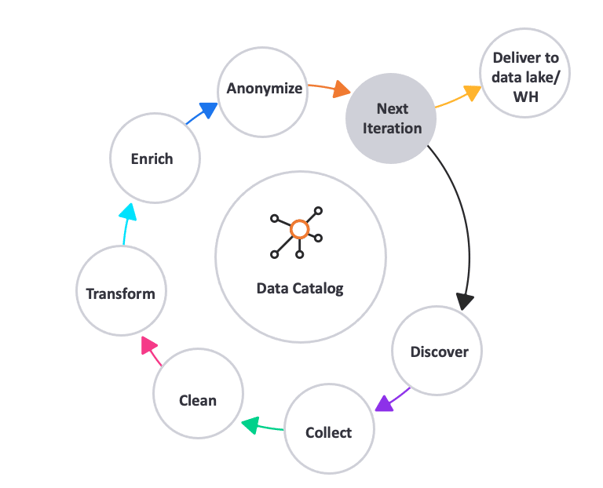
Data Preparation Process Flow
The data preparation process lifecycle consists of the following steps:
-
Data discovery
-
Collection
-
Cleansing
-
Transformation
-
Enrichment
-
Data Anonymization (masking)
Ideally…
-
The data preparation process is automatic, including discovery of all data from all sources (legacy and otherwise), followed by data collection and cleansing.
-
It is then transformed into current, usable formats, and can even be enriched with new data, based on additional sources and processing.
-
The information is made unidentifiable – to protect personal and/or sensitive data – before being delivered to a data lake or warehouse, or recycled for another iteration.
-
The data can be made available to data stores in any ingestion mode – batch mode, data streaming, Change Data Capture (CDC), or messaging – with all data iterations stored, and ready for reuse.
-
The data preparation process can be operationalized – from a self-service, one-off model, into a lifecycle that can be packaged for automation.
Before describing how the ideal can become a reality, let’s have a look at current data preparation tools and trends.
Data Preparation Tools and Trends
There are 3 categories of data preparations tools: standalone, those offered by analytics providers, and those offered by integration providers.
 Niche standalone tools are consolidating into analytics and integration tools.
Niche standalone tools are consolidating into analytics and integration tools.
Standalone tools are self-service products for data scientists and data analysts, however, as Gartner predicts, the trend is for data preparation tools to be consolidated into analytics and integration platforms. Case in point, Paxata was recently acquired by DataRobot.
Analytics tools answer the needs of the business, with a focus on building analytical models, dashboards, and reporting. While this is an important endeavor, data preparation is just one of many elements in an analytics/BI/ML package. Because data integration is not a core competency among these providers, data preparation remains a thin component and will most likely not receive the kind of attention and investment it deserves.
Integration tools are developed for data engineers, with the providers speaking the same language as their IT peers. For vendors like Informatica, K2View, Qlik, and Talend, data preparation is their bread and butter. The depth of knowledge inherent in the world of data integration in all its complexity – accessing sources, mapping, real-time updating, etc. – makes data preparation for data engineers a much richer offering.
Enter Data Fabric Architecture within a Data Product Platform
Enterprises seeking solutions for their data preparation process today, should also be thinking about tomorrow, and give priority to a broader approach. As discussed, if the standalone tools are disappearing, and the analytics tools are likely to fall short on features and updates, that leaves the integration tools to lead the way. For the most part, integrated data preparation tools are part of a data fabric architecture within a Data Product Platform. Data products already have the capabilities to connect to all data sources, process and transform the data, and then make it available to consuming applications. And they can also be used to feed this trusted data into data lakes and warehouses.
 When data fabric is part of a Data Product Platform, Micro-Databases
When data fabric is part of a Data Product Platform, Micro-Databases
organize and manage the data related to every business entity instance.
Data Products – a New Approach to the Data Preparation Process
A Data Product Platform is ideally suited to data preparation. It lets you define an intermediary data schema, aggregating all the attributes of a business entity (such as a customer, or an order) across all systems, and provides you with the tools to prepare and deliver the data as an integrated Micro-Database™.
So, instead of moving data table by table, you prepare and pipeline the data via business entity. In other words, you collect data from all sources into Micro-Databases – cleansing, enriching, masking, and transforming it along the way.
Complete and quick
With entity-based data pipelining tools, the prepared data is always complete. Moreover, transformations are performed at the business entity level (rather than at the table level), reducing performance to a fraction of the time it takes to execute table-level transformations.
Connected and understood
A Data Product Platform consistently delivers data that is connected, and therefore easily accessible for querying in the data lake. And the data product schema is easily understood by business analysts, who have no knowledge of the underlying source systems and data structures.
Analytical and operational
The prepared data in the platform can be delivered to support offline analytical workloads (in data lakes and warehouses) as well as operational workloads – such as a Customer 360, operational intelligence, and GDPR and CCPA compliance – without affecting sources or targets in any way.
Flexible and insightful
A Data Product Platform treats a data lake or warehouse as both a target and a source. For example, insights that are generated in a lake can be pipelined back to be captured in the source systems.
The platform can also:
-
Serve complete and connected data for both operational and analytical use cases.
-
Support the entire data preparation process, and transition it from self-service to full automation.
-
Operationalize the process, by having data engineers build data prep flows, and then package them for reuse by other similar flows and other departments.
-
Apply data governance to control access to data, and ensure compliance with data privacy regulations.
Data Fabric on a Data Product Platform: The Future of Data Preparation
Today’s enterprises need future-proof data preparation tools, such as those found in a data fabric architecture, within a Data Product Platform. A Data Product Platform operationalizes data preparation by turning it into a high-speed service – with split-second, source-to-target, data delivery – and by having data engineers build and package data preparation flows for reuse.

