










Table of contents
Here’s a free high-level synopsis of Gartner’s Market Guide for Data Masking to familiarize data pros with the available technologies and latest use cases.
What is Data Masking?
Data masking is a process that involves transforming sensitive data into non-sensitive, but still useful, information, essential for application testing and operational analytics.
Data masking tools include various de-identification methods, including:
-
Redaction
Redaction is a process that controls secrecy although it can also control privacy, if the proper sensitive data fields are included. Designed for unstructured data masking (say, of photos) or semi-structured data masking (say, of PDFs that combine tabular data with imagery), redaction is typically applied to production environments – but for non-transactional use cases.
-
Data anonymization
Data anonymization refers to a complete data sanitization process, achieved by removing or replacing sensitive data so that it can't be directly associated with a specific person.
-
Pseudonymization
Pseudonymization is similar to anonymization but is reversible by design. So, instead of deleting or replacing PII, pseudonymization stores them separately with a dedicated key used for decryption.
-
Format-Preserving Encryption (FPE)
In the data masking vs encryption equation, FPE is an encryption algorithm that preserves the format of the data while it’s being encrypted.
-
Data tokenization
Data tokenization replaces the value of data with a substitute and is useful for protecting data at rest. It’s also valuable when there needs to be consistent mapping between the token and the original value in order to preserve referential integrity.
Thoroughly Modern Masking
Organizations are increasingly turning to data masking for data de-identification, demonstrating the growing need to scale up data protection measures amidst the modernization of data and analytics architectures.
Additionally, data privacy regulations (listed further on) have initiated a wide range of data masking techniques, which may complicate efforts to establish standards for enterprise data masking.
Today’s enterprises are urged to:
- Treat data masking tools as fundamental to data security and consider combining them with synthetic data generation tools for even broader protection.
- Implement data masking on a wide scale, to minimize fragmentation across data sources.
- Apply data masking at the data virtualization or application level to bolster current tools.
Data Masking Trends
As organizations grapple with the complexities of modern data security landscapes, data masking tools have become critical for any enterprise. Gartner notes that data masking has become:
-
Increasingly important with the global expansion of privacy laws and growing awareness of data security in advanced analytics and training Machine Learning (ML) models.
-
Crucial for meeting compliance, addressing threats, and supporting application-testing use cases and analytics involving aggregate data.
-
A must for the enterprise, with growing attention to dynamic data masking combined with Attribute-Based Access Controls (ABAC).
Meeting Security Needs
Data masking has an evolving role in response to growing data security awareness, particularly in advanced analytics and ML model training. Notably, there's a shift towards cloud-based data lakes, where data masking, while still in use, is gradually giving way to synthetic data generation.
There is an increased focus on safeguarding data from insider threats through the adoption of “0-trust” principles, that precisely define and authorize all access. Dynamic data masking and ABAC in broad-spectrum data security platforms play a crucial role in supporting this trend.
While interest in data masking remains stable globally, the North American market shows a modest decline, with a specific emphasis on verticals reliant on personal data. Dynamic data masking, especially when integrated with ABAC and data catalogs, is gaining traction.
Data masking technology continues to be a vital tool for meeting compliance requirements, addressing insider and outsider threats, and supporting application-testing use cases and analytics involving aggregate data.
Here are a few of the reasons for the growing importance of data masking:
-
Compliance requirements
Compliance requirements span internal policies and various regulatory standards, including PCI DSS, HIPAA, LGPD, GDPR, and PIPL, aiming to protect personal data from unauthorized access and abuse.
-
Insider and external threats
Insider threats rise from increased non-production database use by employees and contractors, posing risks to sensitive data. External threats involve data exfiltration exploiting over-exposed data and compromised insider identities.
-
Security assurance and alternatives
Data masking tools often lack penetration testing against re-identification risks, prompting organizations to seek security assurances from vendors. Synthetic data has emerged as an alternative to data masking in cases where de-identification compromises data quality or utility, particularly in the case of ML model training.
Enterprise-Grade Data Masking Technologies
Gartner lists 3 core technologies required to meet enterprise demands:
-
Static Data Masking (SMD) renders sensitive data meaningless in a non-production environment, allowing enterprises to use realistic – but fake – data for software testing, while protecting the confidentiality of the original data.
-
Dynamic Data Masking (DDM) selectively anonymizes sensitive information within a dataset, allowing only authorized users to access ALL the data, while limiting exposure to everyone else.
-
Unstructured/Semi-structured Redaction (USR) masks specific sensitive data and Personally Identifiable Information (PII) to comply with privacy laws. It controls access to confidential data, but not to non-sensitive information.
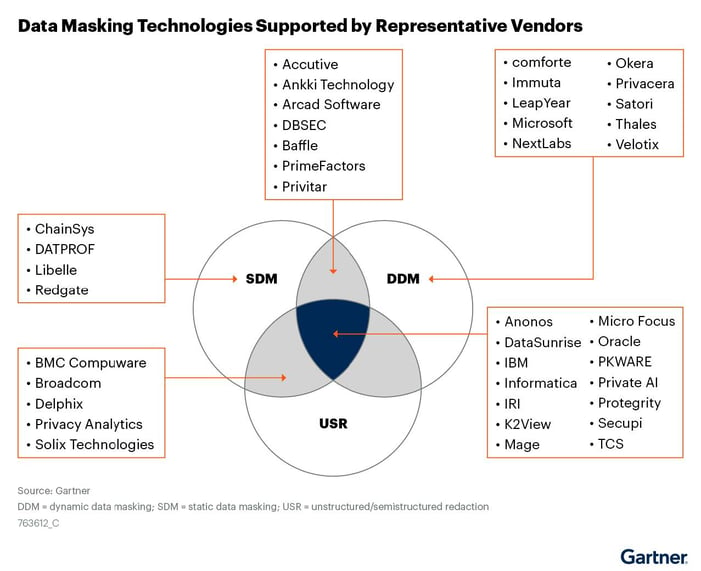 The ideal vendor should support all 3 technologies and provide the following capabilities:
The ideal vendor should support all 3 technologies and provide the following capabilities:
-
Data relationship and PII discovery
The same sensitive data, if present in multiple tables of the same database, should be treated consistently to maintain referential integrity of the masked data in all databases.
And although PII is scattered throughout massive volumes of data, every instance must be detected. Enterprise data masking software needs to automate both these processes.
-
Data masking rules management
Rules need to be defined in a single central user interface so they can be effectively applied across an enterprise, especially when using multiple, cross-referenced databases. Enterprises should look for vendors that offer templates, pre-defined rules and rule wizards, and a list of data masking best practices to ensure users comply with relevant security and compliance regulations.
-
Data masking operations management
Automated discovery processes, integration with data catalogs, and metadata play crucial roles in ensuring consistency and efficiency in defining masking rules. Tools for deploying masking rules, scheduling masking jobs, and monitoring performance are crucial for the full lifecycle management of masking data.
-
Reporting for compliance
Periodic reporting keeps enterprises audit-ready by proving that the appropriate data masking methods were applied. The reports would list data dependencies and relationships, applied techniques, and details of the sensitive data tracked across the different data sources.
Keeping a Steady Eye on the Ever-Evolving Market
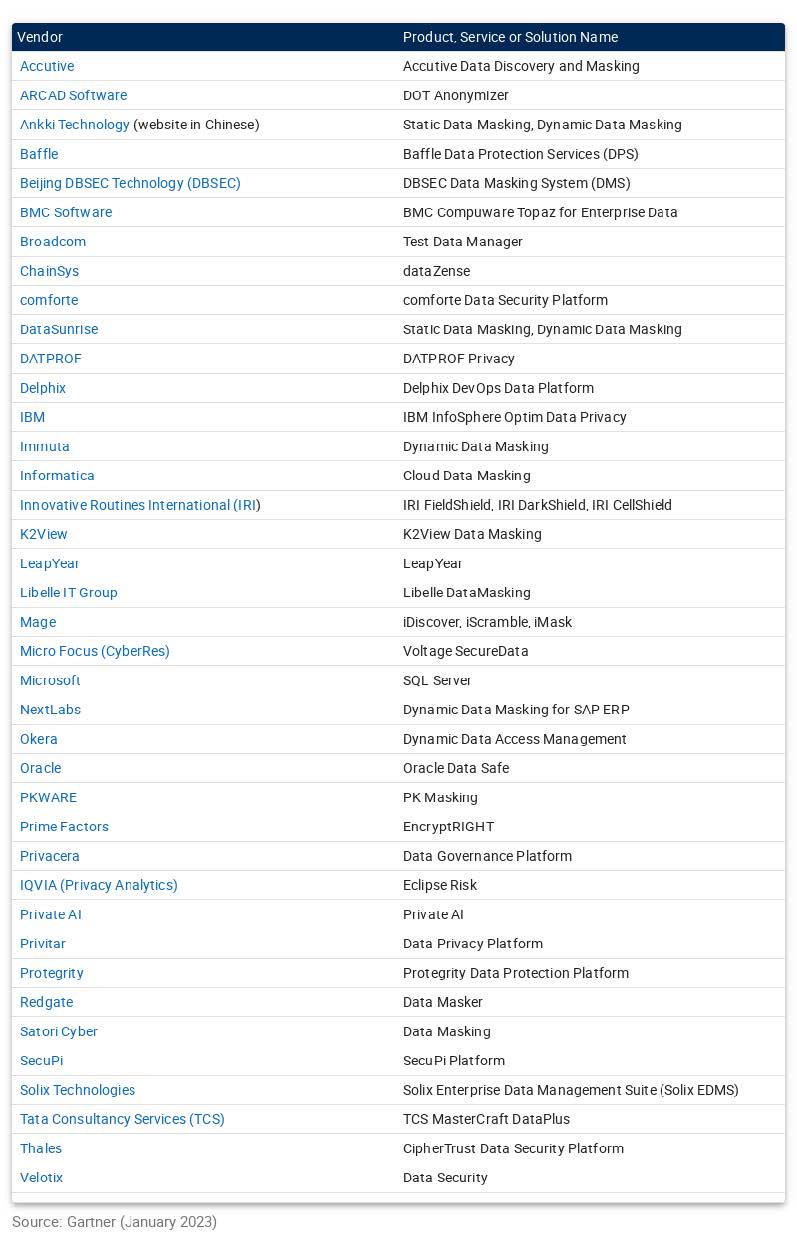
As time goes on, the market for data masking tools continues to grow. Gartner lists the following data masking vendors (in alphabetical order) alongside the tools they offer. K2view, 1 of 3 Visionaries in the Gartner Magic Quadrant for Data Integration Tools 2023, is included in this list. (Most other listed companies were NOT selected for this year’s MQ.)
Entity-Based Data Masking Tools are a Breed Apart
Enterprises with complex data environments are adopting entity-based data masking technology to anonymize sensitive test data quickly and easily. K2view masks structured and unstructured data inflight via business entities – such as customers, invoices, or devices – statically or dynamically, from any data source, while maintaining referential integrity of all the masked data.
Learn more about K2view entity-based data masking tools.

