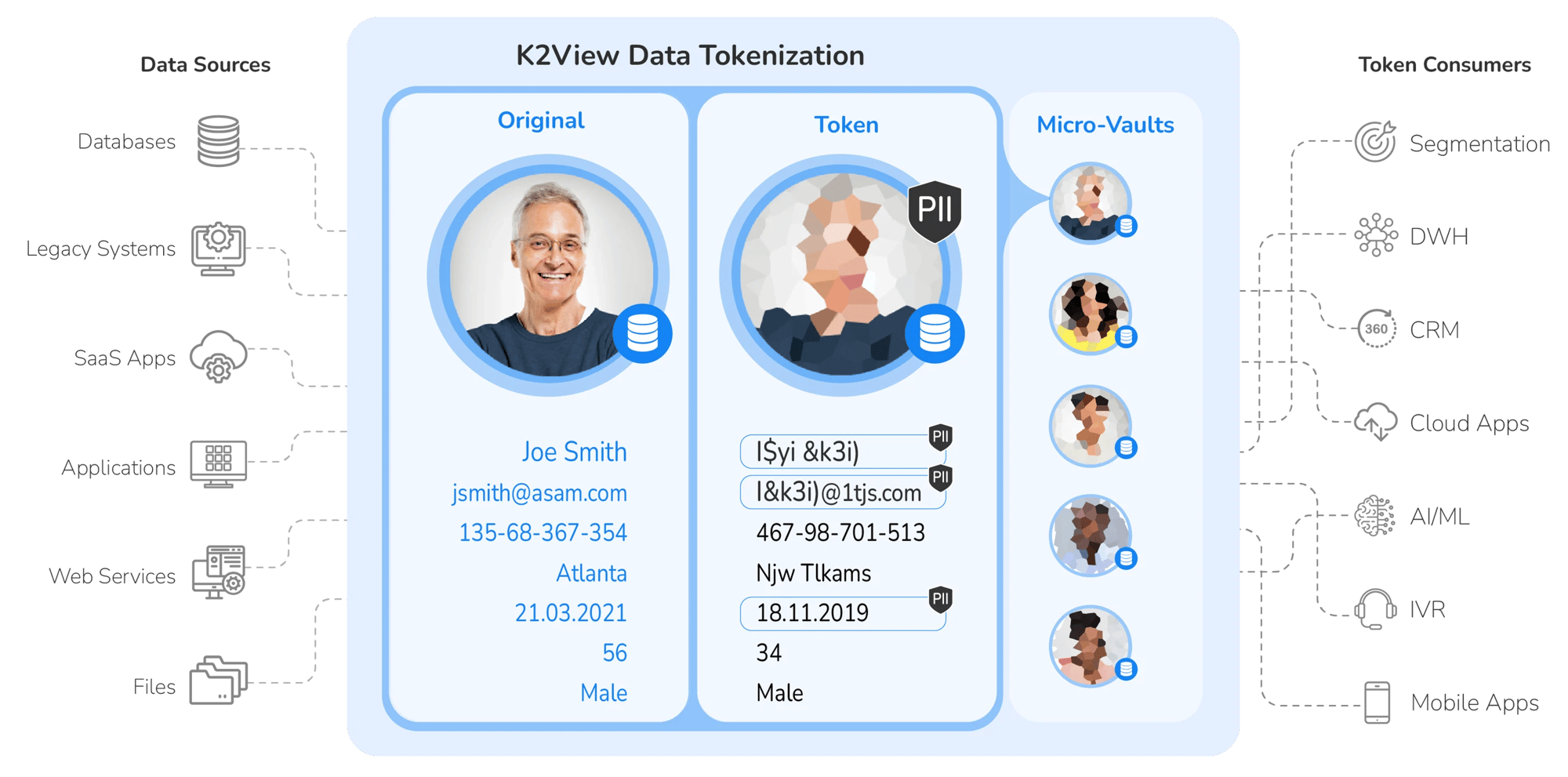
Data tokenization allows enterprises to protect sensitive data while maintaining its full business utility. With tokenization, data consumers can freely access data, without risk.
Data tokenization is essential for today’s businesses because the majority of data breaches are the result of insider attacks, whether intentional or accidental. Consider these enterprise statistics:
- 50% believe that detecting insider attacks has become more difficult since migrating to the cloud
- 60% think that privileged IT users pose the biggest insider security risk to organizations
- 70% feel vulnerable to insider threats, and confirm greater frequency of attacks
What Data Needs to be Tokenized?
When we talk about sensitive data, we're specifically referring to Personal Health Information (PHI) and Personally Identifying Information (PII) .
Medical records, drug prescriptions, bank accounts, credit card numbers, driver’s license numbers, social security numbers, and more, fall into this category.
Companies in the healthcare and financial services industries are currently the biggest users of data tokenization. However, businesses spanning all sectors are starting to appreciate the value of this alternative to data masking. As data privacy regulations become more stringent, and as the punishments for noncompliance become more commonplace, prudent organizations are actively looking for advanced solutions to data protection, that can also maintain full business utility.



 Table of Contents
Table of Contents