









Table of contents
The tokenization of data replaces personally identifiable information with a valueless equivalent that safely enables compliant testing and development.
Table of Contents
Tokenization of data is not just nice-to-have
What is tokenization of data
How tokenization of data works
What information needs to be tokenized
Business entities transform data tokenization
Now is the time to act
Tokenization of data: Not just nice-to-have
Why should you care about tokenization of data?
Let’s start with the fact that the number – and cost – of data breaches are rising every year.
In 2021 there were 1,291 publicly reported data breaches in the US, up 17% from 2020, which had 1,108 reported breaches. A more recent report by IBM found the average cost of a data breach rose 10% over the same timeframe, from $3.86 million to $4.24 million. Interestingly, remote working and digital transformation increased the total cost of a data breach by an average of $1.07 million.
As companies trudge forward in their pursuit of legacy application modernization, and as remote work becomes a permanent trait of modern business, the risk and potential impact of a data breach is rising.
At the same time, the regulatory landscape around data privacy and protection is becoming increasingly stringent. Failing to comply with sensitive data protection standards could lead to dire consequences, including steep penalties, litigation, and reputation damage.
Fortunately, there are ways to protect sensitive data and prevent data breaches. Today, data tokenization is one of the most effective options.
What is tokenization of data?
Unlike the masking of data, aka data anonymization, the tokenization of data is the process of replacing sensitive data with a non-sensitive equivalent, or token, that has no exploitable value.
It’s a method of data obfuscation that helps businesses safely store and use sensitive data while complying with data protection and privacy regulations.
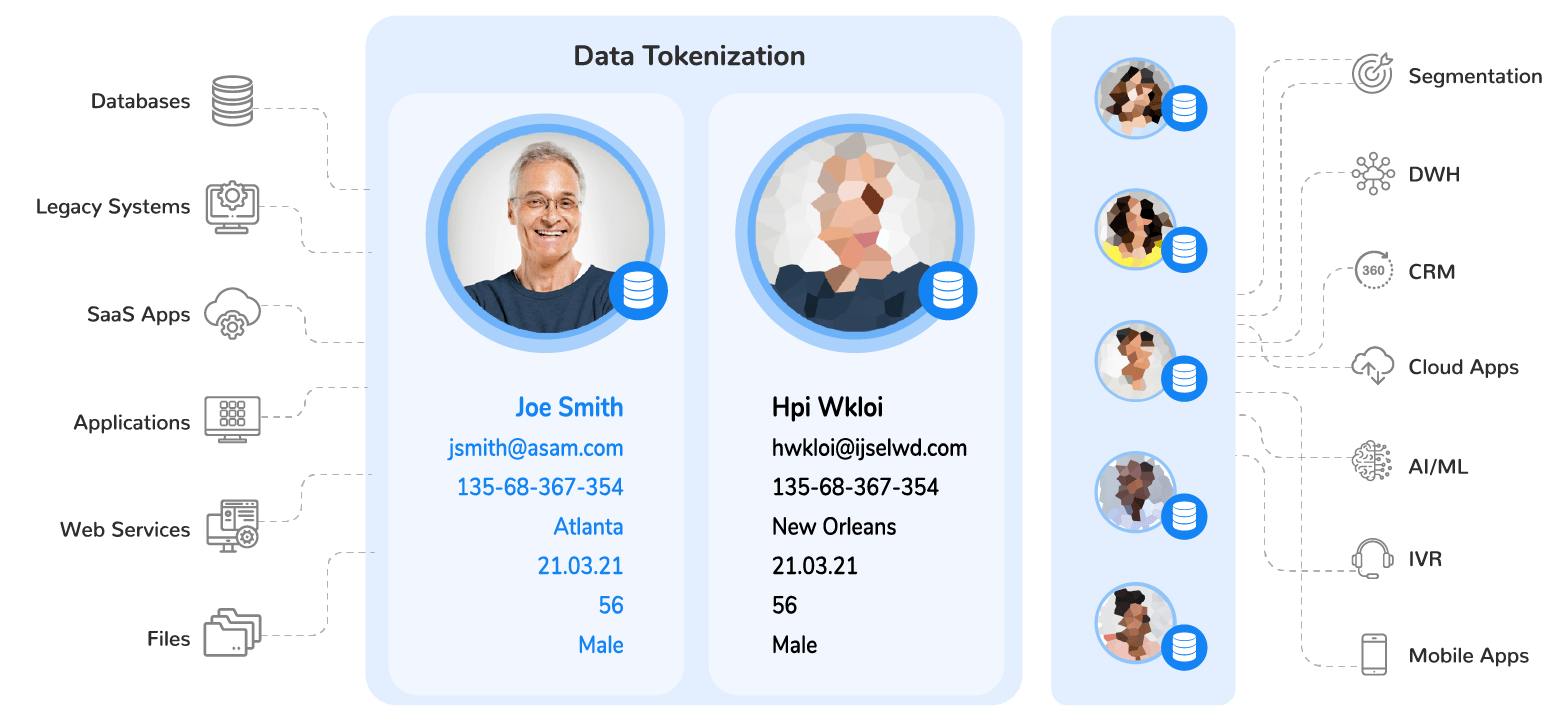
When data is tokenized, it replaces sensitive data – in databases, data repositories, internal systems, and applications – with non-sensitive data elements, such as a randomized string of characters. Unlike sensitive data which could be easily exploited by a malicious actor, a token has no value in the event of a breach.
Original sensitive data is usually stored in a centralized token vault.
How tokenization of data works
Unlike encryption, which uses a mathematical algorithm to create anonymized data, tokenization of data does not use a key or algorithm, by which the original data could be reverse-engineered. Instead, it replaces meaningful values with a randomly generated alphanumeric ID.
Tokens can be configured to retain the same format as the original string of data, for use in operational and analytical workloads. Tokenization also supports data sharing, and enables compliant testing and development, while keeping data protected.
For example, tokenization allows a company that processes credit card payments to substitute the credit card number with randomized alphanumeric characters. The token has no value, and is not connected to the individual who used it to make a purchase, or their account. The actual credit card number is stored in an encrypted virtual vault.
This tokenization of data helps the business comply with the Payment Card Industry Data Security Standard (PCI DSS), without having to retrofit the existing business applications to become PCI DSS-compliant. It therefore reduces the cost for companies to accept, transmit, or store cardholder information, while safeguarding sensitive data against fraud and data breaches.
To reverse the tokenization process, original data is retrieved securely via HTTPS using the original token, as well as authorization credentials. This process is called de-tokenization.
What information needs to be tokenized?
When we refer to sensitive data, we often mean Personally Identifying Information (PII) and Personal Health Information (PHI).
Bank accounts, financial statements, credit card numbers, social security numbers, medical records, criminal records, driver’s license numbers, stock trades, voter registrations, and more fall into this category.
Pandemics emphasize the need to tokenize personal vaccination data.
While healthcare and financial institutions are currently the biggest users of data tokenization, organizations across all sectors are beginning to recognize the value of this data obfuscation method. As data privacy laws expand, and as the consequences for noncompliance get harsher, smart businesses are proactively seeking advanced solutions to protect sensitive data, while maintaining its full business utility.
Business entities transform data tokenization
Business entities are revolutionizing data masking tools and data tokenization tools by delivering a complete set of data on a specific customer, claim, credit card, payment, or store. Every bit of data associated with a business entity is managed within its own, encrypted Micro-Database™.
With a business entity approach to tokenization, all sensitive data is tokenized in its corresponding Micro-Database, alongside its original content. And each Micro-Database is secured by a unique 256-bit encryption key.
This resolves one of the biggest risks associated with conventional data tokenization solutions, which store all of an organization’s sensitive data in one big token vault. A centralized vault – even outside of the IT environment – increases the risk of a mass breach. These vaults might be harder to penetrate, but when an attacker is successful, the results could be catastrophic for a business and its customers.
Moreover, a centralized token vault can lead to bottlenecks for scaling up data and make it harder to ensure referential and format integrity of tokens across systems.
In comparison, entity-based tokenization:
-
Ingests fresh data from source systems continuously
-
Identifies, unifies, and transforms data into micro-databases, without impacting underlying systems
-
Tokenizes data in real time, or in batches, for a specific data product
-
Secures each Micro-Database with its own encryption key and access controls
-
Preserves format and maintains data consistency based on hashed values
-
Provides tokenization and de-tokenization APIs
-
Makes tokens accessible in milliseconds
-
Ensures ACID compliance for token management
Now’s the time to act
The stakes are rising around data protection. Malicious actors are eager to exploit data security vulnerabilities, while internal breaches – even resulting from accidents – remain a monumental challenge for enterprises.
Businesses today need a data protection solution that covers 3 key components:
-
Protection from data breaches
-
Compliance with regulatory standards
-
Support for operational and analytical workloads
With entity-based data tokenization, you enhance the security of your sensitive data, while still allowing data consumers to use it, with minimal risk of an internal breach. As the scale, cost, and damage of data breaches and noncompliance rises, the time for a business entity approach to tokenization is now.

