





Data governance lets large enterprises manage data availability, usability, integrity, security, and compliance – better, faster and more cost-effectively. It also delivers huge business value by capitalizing on data assets and accelerating digital transformation.
Data governance really has only one goal – to deliver business value. In the digital information age, data has become a critical asset. Data-driven strategies can help grow revenues, increase profits, and beat the competition. Real-time, data-driven decision-making improves multi-channel customer experiences, and satisfaction.
With ever increasing volumes of data, the pace of digital business, mounting regulatory pressures, and a jungle of enterprise systems, it’s easy to get lost in the data. In fact, data governance initiatives often fail to deliver business value because they start and end with a focus on data.
This white paper presents a new, business-focused approach to data governance. Governing data in real-time with data products promotes the cross-functional collaboration needed to drive business outcomes.
There are many drivers for adopting data governance. Each one is both complex and compelling. Together they present a daunting challenge that’s getting more complicated by the day.
To get the right data to the right people at the right time – in a secure and compliant way – data governance leaders need to manage availability, usability, integrity, security and compliance of enterprise data.
When it comes to the role of data governance, Forrester Research borrowed the phrase “protect and serve”. Protecting data due to regulations, privacy and cost requirements, while serving data for strategies, growth and opportunities – this concept is at the core of data governance.
With layers of complexity and conflicting demands across the enterprise, data governance teams must focus their investments carefully. It is easy to see why data governance leaders struggle to engage business stakeholders in multi-layered, data-driven initiatives. Without business focus, it is equally easy to understand how such projects fail to deliver business value.
The challenges in governing data can be classified into three main categories:
Most data governance initiatives are data-centric, and this, according to Gartner, is the wrong approach. Instead, they should focus on business outcomes, processes and key performance indicators (KPIs) using concrete measurable metrics.
The cost of data-centric governance initiatives is even higher, when you consider that this approach fails to engage business leaders. When key business stakeholders are not engaged and invested, it is difficult for data governance leaders to know how and where to invest.
“Technical, complex and data-centric business case leaves business-people feeling confused, disconnected and uninterested.”
Gartner
Data and analytics leaders often make governance investments, but then do not track them against directly attained business value. Setting the ROI goals, defining clear metrics and tracking them is paramount for success.
Needed: business-focused data governance
Data governance really has only one goal – to deliver the desired business outcomes. Delivering on this promise requires a new approach for data governance. This approach must be business-focused at its core. It should be approachable, easy to understand, and easy to measure, to engage business leaders and gain executive sponsorship.
Adopting a data governance approach does not mean choosing between data operations and strategy. According to Gartner, it should be anchored in both data strategy and operation models. Forging this connection ensures that data-driven vision and business outcomes provide the forward momentum, while the day-to-day operations and IT Infrastructure ground strategies in reality.
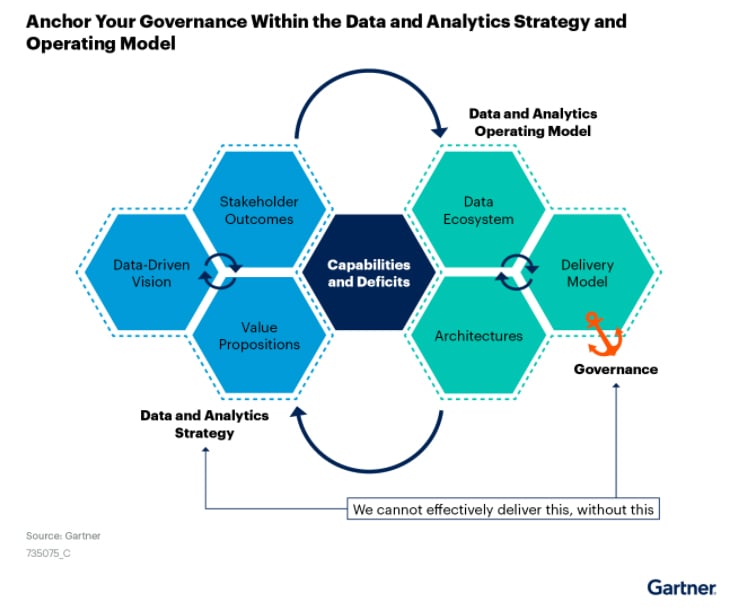
Source: 2021 Gartner report entitled, “Take a Personalized Approach to Data and Analytics Governance”
The right data governance model is one where technology fades to the background, and where data-driven experiences are spotlighted. Ambient data governance is the term coined by Forrester to highlight that “data should just work the way your digital experiences do.”
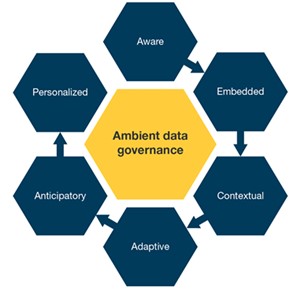
Source: 2019 Forrester report entitled, “An Advanced Course In Data Governance: Ambient Data Governance Makes Data Work”
A data product is a reusable data asset, engineered to deliver a trusted dataset, for a specific purpose. It integrates data from relevant source systems, processes the data, ensures that it’s compliant, and makes it instantly accessible to anyone with the right credentials.
A data product generally corresponds to one or more business entities (customers, suppliers, devices, orders, etc.) and is made up of metadata and dataset instances. It uniquely manages each dataset instance in its own hyper-performance Micro-Database™, to achieve enterprise-grade scale, resilience, and agility.
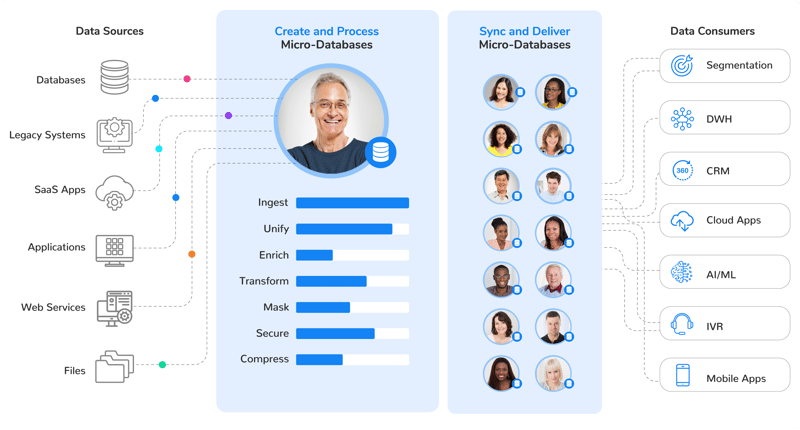
Governing data by data products creates a common business language, providing the basis for collaboration between data and business teams. It focuses the discussion on the business by "rising above the noise" created by the underlying source systems, their technologies, and data formats.
Using data products to catalog data, creates an inventory of data assets that is always up to date. It also provides dynamic data lineage, mapping data flows from source to target. An active metadata layer delivers real-time performance and usage information. Full visibility into when, how and how often data is used, makes it easier to secure, protect, and scale data delivery.

The data product schema can be enriched with metadata that adds meaning and value to the specific business entity’s data. For example, metadata can be used to create multi-layer data classifications, add data lifecycle information, define consent parameters, and more. It can also be used to add active metadata information about usage of the data by consuming applications and users. This provides a direct connection from the data governance policies and regulations to the data.
A single, complete source of a business entity data and metadata – coupled with centralized business rules – provides effective real-time data governance that can keep up with the pace and scale of your digital business. Based on your data classifications and rules, you can prevent access, or mask, the data, as needed, and secure and deliver it in an instant.
From data ingestion, access, and delivery to end-of-life management, data products provide the context and means to simplify data management, while complying with privacy laws, industry regulations, and user preferences. For example, a customer Micro-Database can readily address consent-based data collection and processing. It can also provide the semantic context for balancing data storage limitations, and a solution for the need to save financial information for 7 years.
A data product approach is ideal for integrating with, and enhancing, the capabilities of enterprise data and analytics investments. It can be used to:
Let’s take a specific use case to showcase how data products provide an effective, business-focused approach to data governance.
It's broadly accepted that the cost of acquiring a new customer is 5x higher than retaining existing customers. That’s why reducing churn is a strategic business objective for many companies. The first step towards achieving this goal is to understand the factors that contribute to churn, and identify the customer behavior that indicates this intention.
You may assume that modeling the customer data product is a data function, but a good place to start would be with the business. The customer data product unifies fragmented customer data from different IT systems and environments. Depending on the business goal, you could collect all enterprise customer data, or focus on the relevant sources for a specific use-case, and perhaps expand the scope over time. Deciding on the right approach brings together the business owners, IT, and data governance teams into a discussion concerning the type of customer information that may impact the business goal.
In the case of customer churn, evaluating the data sources related to the top reasons why customers leave, is a good place to begin. Here are the top 3:
Relevant data can also be found elsewhere, outside the enterprise. Dissatisfied or disgruntled customers often resort to social media, mostly because it’s so much quicker to tweet, or post, than writing an email, filling out a form letter, or calling a support number. This means that a customer’s social media feeds may contain churn indicators that should be connected to the customer entity.
Before the data can be used for any purpose, you want to make sure that sensitive and personally identifying information (PII) is protected as required by privacy laws. By governing business entities, you can embed the data privacy protection.
Working with the customer entity schema, identify and classify the sensitive information with the help of legal and privacy experts. This classification information is added as a metadata enrichment layer that correlates to data items like names, location, IP addresses, health records and more, that need to be protected.
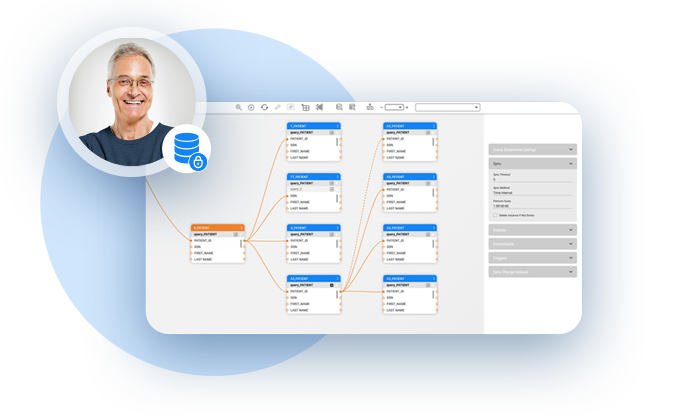
Having sensitive data classified in a Micro-Database, makes it easier to protect personal information without slowing down data operations.
Going back to our customer churn example, the churn prediction model requires the business intelligence team to run deep machine learning on a subset of the customer population.
Since the data is already organized into Micro-Databases that contain all relevant data about each customer, the heavy lifting required to create a complete trusted dataset has already been done. With the help of the classification layer, fields that need to be protected are anonymized before the dataset is delivered to the analytics team. In this way, compliant datasets can be provisioned for analytics in minutes.
Providing a personalized customer experience and personal privacy protection apply to every customer. Combining them into a single Micro-Database, makes it easier to deliver on both.
This is also a good time to discuss customer consents and preferences, and their impact on marketing.
It’s important to point out that not all privacy laws are created equal. GDPR, for example, requires informed consent (“opt-in”) before any personal data is collected, whereas CCPA does not. With all the new data protection laws being enacted in the US and around the globe, it’s hard to know how this consent issue will play out.
To sustain compliance, data governance will need to continuously answer the question, “Can we collect personal information?” for every individual customer. With a data product approach, this question can be answered with a straightforward algorithm that applies geography-based rules to the residence and consent preferences. Since the unified consent permissions in the customer Micro-Database are always up to date, any changes the customer makes can be automatically and immediately honored.
For example, under GDPR, you can collect personal information if you have a lawful basis for processing, such as:
By combining this classification with individual consent information, you can ensure legitimate data collection. In addition, any changes to individual consents and preferences are saved in the customer Micro-Database, serving as proof of compliance for audit purposes.
This approach enables you to comply with regulatory requirements, and build trust, by responding quickly to customer requests.
Once your business intelligence team identifies the causes and likelihood of churn, and create a model for it, it’s time to bring the marketing team into the picture. Since the customer Micro-Database contains everything the company knows about the specific customer, the marketing team can take a data-driven approach to the problem. Its job is to prevent a customer from leaving at the crucial moment of intent. Churn prevention tools include personalized promotions and compensations that are tailored to the customers’ preferences.
Now, when a user logs in to the self-service portal, real-time analytics are performed on the customer’s data against the churn model. If the customer has just spent over 10 minutes holding the line for customer support before abandoning the call – a high propensity to churn is likely.
Marketing analytics now spring into action to generate the next best action. The solution may include a sincere apology, an explanation of the long waiting time, and preference-based compensation – all in real time.
Sally waits 10 minutes for support, and gives up -> She logs onto the self-service portal. -> Identified as “churn risk” by real-time analytics, Sally instantly receives a retention offer… -> …and gladly accepts it
As the amount of data increases, the need for data governance increases. With a data product approach, data governance leaders join forces with business stakeholders to drive business value by unleashing the power of data-driven solutions and reaping the rewards of digital commerce.
