
.jpg)


Table of contents
This post explores strategies for MCP servers to generate purpose-aligned, token-efficient prompts for MCP clients—ensuring effective communication while optimizing performance and resource usage.
Smarter context injection
As enterprises deploy Large Language Models (LLMs) in customer-facing and back-office workflows alike, it’s easy to fall into a familiar trap: “We gave the model everything – timelines, tables, logs, and notes – yet it still gets it wrong.”
You LLM responds inaccurately not because it lacks intelligence, but because it lacks precision. Bloated prompts with excessive or irrelevant data confuse the model, increase latency and cost, and raise the risk of LLM hallucination issues. The solution isn’t more data; it’s smarter context injection.
Enter the MCP AI.
In earlier posts, we explored how MCP enforces guardrails at runtime, supports real-time harmonization of fragmented data, and optimizes for latency in context delivery. In this post, we focus on how MCP helps construct purpose-aligned, token-efficient prompts that improve both LLM accuracy and governance.
The MCP client-server architecture makes LLMs highly effective in operational use cases like conversational AI for customer service.
MCP works together with a data layer, often accompanied by generative AI (GenAI) frameworks – like Retrieval-Augmented Generation (RAG) or Table-Augmented Generation (TAG) – which integrate real-time enterprise data into LLM prompts resulting in more precise answers to user questions.
Why LLMs need precision, not overload
A large language model doesn't search through a prompt as a person would. Instead, it relies on internal statistical reasoning over patterns and token context. If the prompt includes too much irrelevant or noisy information, the signal-to-noise ratio suffers.
Typical symptoms of unstructured or overloaded context:
-
Repetition or contradictions across fields
-
Poor time ordering due to inconsistency or ambiguity
-
Data duplication or entity drift
-
Prompt truncation due to token overuse
The cost of prompt overload
| Aspect | Overloaded prompt | Precise prompt |
| Token count | 4,000 | 800 |
| Hallucination risk | High | Low |
| Latency | 2.5s | 600ms |
| Accuracy | Low | High |
| Cost per prompt | High | Low |
Overloaded prompts increase cost and reduce model quality.
With a leaner, better-scoped prompt, the model is more likely to respond more accurately, quickly, and consistently. When it comes to LLM prompt engineering, precision isn’t just a cost benefit; it’s a quality driver.
Precision in the MCP pipeline
MCP’s job isn’t simply to fetch data. It must match the intent of the LLM task to the right subset of enterprise data, and it must also understand the context of that data to represent it faithfully.
Matching use intent and understanding context involves 2 critical layers:
- Intent-aligned selection
What is the user asking the model to do? (For example, summarize, recommend, explain?) - Context-aware interpretation
What does the retrieved data mean, and is it valid for this use case?
To support these layers, MCP relies on:
- Entity resolution
Ensuring records are cleanly joined and not duplicated - Data quality enforcement
Validating recency, correctness, and consistency - Rich metadata
Tags for field meaning, sensitivity, time relevance, and system of origin
MCP precision pipeline
 z
z
The MCP pipeline orchestrates structured context
based on user intent and data meaning.
Precision builds on what we explored in our earlier post, “From prompt to pipeline with MCP” – context must be accurate before it can be concise.
Strategies for prompt precision in MCP
A well-designed MCP implementation makes precision a priority. Strategies for more precise AI prompt engineering include:
-
Use structured prompt templates
JSON snippets, bullet lists, or question-answer formats help LLMs focus.
-
Trim irrelevant fields
Don’t inject every object property, just the ones relevant to the current intent.
-
Flatten over-nested data
Deep hierarchies confuse language models.
-
Resolve and deduplicate entities
Ensure one clean, consistent representation per entity.
-
Reinforce chronology and recency
Time-sequenced context often improves reasoning.
-
Cap long histories
Inject only the most recent or significant items when context length is limited.
Intent-to-data alignment
| Prompt intent | Data retrieved | Data injected |
| Summarize account | Recent tickets, NPS, status | Bullet list with tags |
| Recommend action | Purchase history, device usage | Condensed table with rules |
| Escalate issue | Call logs, SLA faults, tone cues | Time-stamped JSON array |
Different prompt intents require different data scopes and formatting strategies.
The strategies for prompt precision in MCP tie back to what we discussed in our post, “MCP guardrails ensure secure context injection into LLMs” – precision is not a cosmetic feature; it’s a governance necessity.
Entity-aware, intent-aligned prompt construction
The K2view Data Product Platform enables MCP to achieve context precision in real-time. Every business entity (customer, order, loan, or device) is modeled through a data product containing rich metadata including field meaning, priority, sensitivity, and lineage. MCP leverages this data about the data to construct context differently based on the LLM’s intent.
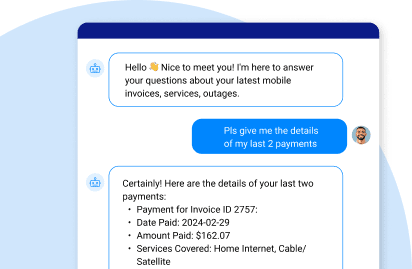
For example, a customer support chatbot might get structured facts and recent events. An AI virtual assistant used for data analysis might get metrics and status summaries. And an escalation generator might get time-stamped records with tone markers. Each prompt is built from clean, filtered, resolved data drawn from live systems but governed by intent.
And, as we covered in our earlier post, “Latency is the hidden enemy of MCP”, all of this happens at the speed of conversational AI.
The result? Lower token count, higher trust, and dramatically better results.
K2view MCP data integration empowers your LLMs with harmonized, business-ready data.
Why MCP has become the de facto protocol for GenAI
A Practical Guide
Learn how to use MCP to connect your GenAI apps to enterprise data in real time - securely, accurately, and at scale.