









Table of contents
RAG, fine-tuning, and prompt engineering are all techniques designed to enhance LLM response clarity, context, and compliance. Which works best for you?
RAG vs fine-tuning vs prompt engineering compared
Large Language Models (LLMs) are impressive tools that have changed the way we work, play, and live – but they're not perfect. They can do amazing things, from writing poems to coding, but they also have limitations that sometimes hinder their usefulness in real-world settings.
LLMs rely on the static data they were trained on. Retraining LLMs on updated or domain-specific datasets is costly and time-consuming, making the model’s ability to access and process up-to-date information very limited. Stale data can lead to incorrect responses to queries, also called AI hallucinations, with potentially damaging consequences to business.
To counter this problem, 3 main methods have been developed, notably:
1. RAG
RAG (Retrieval-Augmented Generation) is a generative AI framework that leverages private knowledge sources to enhance LLM performance. The most sophisticated of LLM response-enhancement techniques, RAG intercepts a prompt, identifies relevant information from internal and external sources, and then augments the prompt with the additional information – leading to a better, more relevant response.
Implemented correctly, RAG has the potential to significantly enhance the factual accuracy, relevance, and domain-specificity of LLM outputs. Note that the effectiveness of RAG depends, in part, on very precise prompt engineering to guide the retrieval system towards the most relevant information.
2. Fine-tuning
Fine-tuning is a process designed to help a pre-trained LLM excel at specific tasks. It facilitates LLM grounding by exposing the model to additional data relevant to the application in question. However, while fine-tuning can significantly enhance response accuracy for specific purposes, it’s also resource-intensive and time-consuming. What’s more, models that have been fine-tuned for specific tasks are often less adaptable to new tasks or unexpected changes.
3. Prompt engineering
Prompt engineering is a technique focused on optimizing the input provided to your large language model, typically facilitated by LLM agents and LLM function calling. By carefully crafting the wording and information contained in each prompt, prompt engineering can shape the model's output. Prompts can be categorized into various types, including task-oriented, content-specific, question-answering formats, and chain of thought prompting.
Effective prompt engineering requires a deep understanding of the LLM's capabilities and limitations. By providing clear instructions, context, and desired formats, prompt engineering can mitigate some of the inherent shortcomings of basic prompts.
RAG vs fine-tuning vs prompt engineering use cases
To unleash the potential of LLMs, we need to provide clear instructions – in the form of prompts. An LLM prompt is text that tells the model what kind of response to generate. It acts as a starting point, providing context and guiding the LLM towards the desired outcome.
To use your LLM most effectively0, you should know when to use RAG vs fine-tuning vs prompt engineering. The right choice depends on the specific requirements of a given use case.
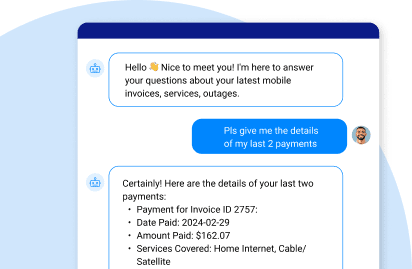
- RAG should be used when factual accuracy and up-to-date knowledge are crucial. For example, the RAG chatbot of a healthcare provider must not only be able to provide general information about treatments and medications, but should also be able to personalize its response by patient, including current condition, medical history, and known allergic reactions to drugs, etc.
- Fine-tuning might be the method of choice for a narrowly-defined task – like a sentiment analysis model tailored to analyze product reviews. The retrieval-augmented generation vs fine-tuning question has different answers, in terms of when to use what, worthy of careful consideration.
- Prompt engineering, known for its flexibility and adaptability, may be ideal for apps requiring a diverse array of responses, like open-ended question/answer sessions or creative writing tasks. Market-leading RAG solutions make use of the latest techniques, like chain-of-thought prompting.
Ultimately, the choice between RAG vs fine-tuning vs prompt engineering comes down to careful consideration of several factors such as desired outcome, available resources, and the nature of the data.
The table below summarizes these considerations:
| Factor | RAG | Fine-tuning | Prompt engineering |
| Customization | Moderate | Limited | High |
| Accuracy | High (real-world knowledge) | High (specific task) | Moderate |
| Complexity | High (retrieval model setup) | High (retrieval, training) | Moderate |
| Data integration | High (private sources) | Limited | Limited (indirect) |
Prompt engineering is an essential RAG component
Active retrieval-augmented generation enhances LLM capabilities by incorporating additional knowledge – from trusted private sources – into the process of generating text. Here's how it works:
Effective prompt engineering is key to fulfilling the promise of RAG. Why? Early-generation RAG solutions were challenged to retrieve relevant information, interpret the data they did retrieve, and then generate contextually intelligent and coherent outputs – without risk of generative AI hallucinations. To address these limitations, precise and detailed RAG prompts, created by a next-generation technique, are essential.
Advanced RAG prompt engineering solutions create clear instructions that explicitly define the requested information and identify the exact type of data required by the LLM. Whether the query requires factual details, historical context, or research findings, next-generation RAG prompt engineering creates clearer instructions for more targeted responses.
RAG prompts also need to offer explicit instructions to the LLM on how it should process and incorporate the retrieved data. They must ensure the LLM focuses on pertinent information and avoids generating misleading or irrelevant content. Finally, advanced RAG prompt engineering helps match the output’s language style and tone to the those of the user. For example, a legal query would require a formal, informative tone, while a customer service interaction would require a lighter conversational style.
Tools like K2view GenAI Data Fusion help realize the full power of RAG prompt engineering. With real-time data retrieval and chain-of-thought prompting, LLMs deliver complete, compliant, and contextual outputs.
Chain-of-thought prompting powers K2view RAG tools
The RAG architecture behind K2view GenAI Data Fusion enables LLM grounding in real-time enterprise data from any source. It leverages CoT (Chain-of-Thought) prompting to enhance any AI data app, while reducing RAG hallucinations. For example, it enables retail chatbots to incorporate real-time customer data and provide hyper-personalized responses. What’s more, GenAI Data Fusion integrates:
- CoT prompting for real-time identification and retrieval of entity data
- Inflight data masking of PII (Personally Identifiable Information)
- Instant resolution of data service access requests and next best action advice
- Access to all enterprise systems via API, CDC, messaging, or streaming methodologies
GenAI Data Fusion incorporates both RAG and prompt engineering – as an alternative to fine-tuning – to ground LLMs for more accurate, relevant, and secure responses.
Discover GenAI Data Fusion, the K2view suite of RAG tools with built-in prompt engineering.

