










Table of contents
When deploying enterprise RAG, you may want to give your LLM’s agents and functions direct access your operational systems. But that’s not a great idea.
LLMs need real-time access to enterprise data
The need for real-time access to structured enterprise data for generative AI has become clear. Many companies are turning to Retrieval-Augmented Generation (RAG) to make it happen, while considering direct access to their operational systems.
What this approach essentially means, is that the LLM agents and functions will have direct access to the data that resides within your enterprise systems. Direct access offers several advantages, including real-time data access and retrieval, as well as more accurate and personalized responses.
But, as illustrated in the diagram below, this can quickly become a mess – aka spaghetti code – that’s very hard to contain, let alone maintain.
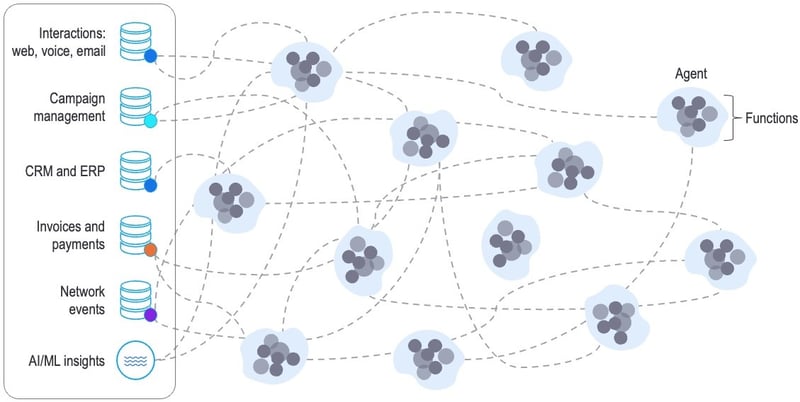
The pitfalls of connecting LLMs to source systems
Despite the advantages, there are also significant limitations in using the direct access approach for enterprise RAG, including:
1. Data integration challenges
- Integration complexity
Source applications typically feature intricate data structures, APIs, and security protocols that are not inherently compatible with direct integration with agents and functions. Integrating your LLM with data from your source systems demands considerable effort in understanding the apps and aligning with their particular architectures and data structures. - Maintenance and upgrades
Source systems are subject to frequent updates and modifications. Integrating LLM agents and functions directly with the apps means that any alteration in the source application could require corresponding adjustments in the LLM integration. This close linkage necessitates meticulous planning to foresee and address potential disruptions stemming from new releases. This precaution ensures that such changes do not undermine the integrity of the LLM integration. But it also imposes a maintenance burden and heightens the risk of compatibility issues over time. - Integration testing and error handling
Integrating your LLM with data directly from your source systems leads to more intricate testing scenarios and greater difficulty in isolating and debugging issues. It also may complicate the management and response to various error scenarios and pose challenges in delivering meaningful feedback to users.
2. Privacy and security risks
Integrating LLM agents and functions directly with source applications increases the risk of exposing sensitive data to unauthorized users, making it advisable to:
- Establish appropriate access controls for each source application – essentially, controlling users, functions, and data access.
- Embed LLM agents and functions with “hard-coded” logic to access and query particular objects, tables, or fields. However, although such logic may prevent data misuse, it might also result in rigid agents that can only respond to predefined queries.
3. Performance and source operational impact
LLMs are computationally intensive models that require substantial resources for inference and training. Deploying your LLM directly over your source applications could lead to unpredicted and significant load on your source system – potentially causing performance issues, slowdowns, or disruptions in the application's normal operation – particularly in a production environment
4. Flexibility and customization
- Limited flexibility
LLM Agents are typically designed for independent operation, enabling flexibility in deployment and customization tailored to specific use cases. Embedding them directly within source applications could curtail such flexibility and increase the difficulty of adapting the model to diverse contexts or environments. - Multi-source integration
Some LLM agents require cross application data to operate and direct access to sources (potentially based on different technologies), making the process of integrating such data very complicated.
5. Knowledge, expertise, and management
- Data compatibility
Source “raw” data is often not an ideal format for LLM consumption. Simply put, the data is not necessarily stored in a way that the LLM understands. Moreover, the absence of a unified data model across different sources requires in-depth knowledge of each source's data structure – including object names, table layouts, column definitions, their business significance, and data integrity constraints. This extensive knowledge is crucial during the creation of agents and functions – and becomes even more critical with each new release of the source application or introduction of new business requirements. Thus, expertise in this area becomes both essential and costly. - Complex management and high cost
Due to the multitude of specific tasks, diverse user requirements, and complex scenarios found in large-scale, dynamic environments, companies often find themselves developing hundreds, if not thousands, of agents. Each of these agents necessitates specialized knowledge of both the business domain and the intricate data structures mentioned earlier. Managing such a large quantity of agents becomes exceedingly complex and incurs substantial costs for the organization.
Optimizing enterprise RAG with K2view
To summarize, we’ve seen that providing generative AI apps with direct access to data inside operational systems can quickly become spaghetti code that’s hard to maintain. There’s an inherent risk of putting additional load on operational systems and harming their performance. And there’s greater risk of exposing sensitive data to unintended access.
These limitations make direct access to operational systems less suitable for active retrieval-augmented generation. As a result, some companies turn to data lakes as an alternative solution. Read about the pros and cons of using data lakes when implementing RAG for structured data.
K2view offers a different approach to how you organize your data for generative AI. As opposed to “macro” data lakes, K2view GenAI Data Fusion supports a “micro” approach that organizes all the relevant enterprise data into 360° views of any business entity (e.g., all the data related to a single customer) – making sure you’re always ready for any question, by anyone, while never exposing any compromising sensitive data to the LLM.
RAG AI is a powerful alternative to storing and transforming data in traditional data lakes. It bridges the gaps to ensure your generative AI apps are equipped with the freshest, most relevant data possible.
Learn more about the market’s leading enterprise RAG tools – GenAI Data Fusion by K2view.

