
.jpg)


Table of contents
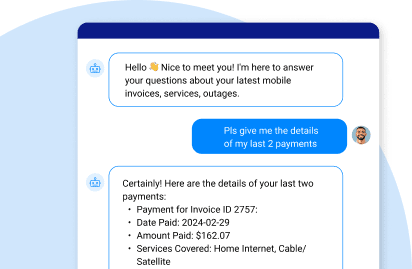
Think about a call center rep asking an AI assistant, “When Richard Jones called last week, we said we’d switch him to the family plan. Did we?”
Harmonized real-time context is a game changer
In the enterprise, generative AI (GenAI) is increasingly used to help frontline employees, like call center agents, get fast answers without having to navigate dozens of disconnected systems.
To answer an operational query, such as the one posed by the call center rep, an AI virtual assistant must instantly pull relevant data from voice transcripts (via NICE), the ticketing system (via ServiceNow), and the billing platform (via Amdocs). It must identify the correct customer, locate the relevant call, extract the commitment, and verify if the plan was changed – all within conversational AI latency.
Without harmonized, real-time context, this type of interaction either fails or delivers incomplete or untrustworthy results.
As enterprise teams race to embed LLMs into workflows, one challenge keeps surfacing: delivering real-time, multi-source context to LLMs in less than a second.
In this post, we’ll explore why latency is the silent killer of AI customer service – and how to architect around it using MCP AI, an orchestration layer for AI implementations, and a business entity approach to data integration.
What is conversational latency?
Conversational latency refers to an end-to-end response time of under 300 milliseconds. Anything more than that starts to feel sluggish, especially in chat or voice-based applications.

Where does the time go?
-
User input processing =10ms
-
Intent parsing and task planning = 15ms
-
Data retrieval (multi-system) = 120ms
-
Harmonization and filtering = 60ms
-
Prompt construction = 20ms
-
LLM inference = 75ms
_________________________________________
Total = 300ms (if you're lucky!)
Why latency kills LLM grounding
LLMs don't know your customer interactions, plans, or transaction histories. To provide relevant answers, they need fresh context at runtime. That context often lives across multiple systems – like voice transcripts, company docs, and billing platforms – and must be retrieved, joined, filtered, and formatted. If that process takes too long, you:
-
Fall back on stale or cached data.
-
Cut corners on context quality.
-
Provide ungrounded responses risking inaccuracies.
In summary, SLOW context leads to irrelevant answers, while NO context leads to AI hallucinations.
Context latency is caused by:
-
Multi-hop data retrieval
Querying Salesforce, ServiceNow, Amdocs, and 2 other systems? Each adds latency.
-
Cross-source joins and reconciliation
Linking customer IDs and merging schema variants takes time.
-
On-the-fly enrichment
Transforming data (flattening structures, formatting dates, translating codes) adds overhead.
-
Data masking
Before reaching the LLM, data often needs to be masked for security and compliance.
Best practices for split-second context access
Here are 5 ways to access context in under 300 milliseconds:
-
Organize context around business entities
Structure data by Customer, Order, Device, etc.
-
Adopt a data product approach
Define schemas for consistent access.
-
Pipeline or prefetch context
Predict needed context based on flow, role, or AI recommendations.
-
Use prompt-scoped caches
Cache common context slices and invalidate intelligently.
-
Summarize or filter long content
Inject only what’s relevant and summarize when necessary.
Sample case study with a 250ms response time
Let’s take another look at our original prompt:
When Richard Jones called last week, we said we’d switch him to the family plan. Did we?
To answer this question, the system needs access to:
-
Voice transcripts (via NICE)
-
Ticketing system (via ServiceNow)
-
Billing platform (via Amdocs)
Instead of making three API calls, the system queries:
GET /context/customer=Richard_Jones/ACME123
This endpoint returns a harmonized, scoped, pre-joined context object with:
-
Voice call history
-
Ticket status
-
Billing adjustment
MCP formats this into a prompt and the LLM responds.
Total round trip: 250ms.
MCP and K2view deliver context as fast as you talk
MCP delivers a superior AI customer experience by working together with a K2view semantic data layer enriched by generative AI (GenAI) frameworks – like Retrieval-Augmented Generation (RAG) or Table-Augmented Generation (TAG). RAG and TAG retrieve and augment relevant enterprise data to enable quicker, smarter LLM responses to user queries.
At K2view, we’ve designed our Data Product Platform specifically to meet the conversational AI latency challenge because:
-
Each business entity (customer, loan, order, etc.) is modeled as a data product.
-
Each data product connects to all relevant enterprise systems to create a unified 360° view of the customer.
-
Context is accessed in real time through a single, governed API call.
-
PII is masked, access is scoped, and latency is predictable.
Best of all, our platform acts as a universal MCP server that delivers LLM-ready context in milliseconds.
So, whether you're building a customer service chatbot or virtual assistant, K2view ensures your GenAI app always has the context it needs.
K2view MCP data integration transforms fragmented data
into clear, actionable context for your LLMs
Why MCP has become the de facto protocol for GenAI
A Practical Guide
Model Context Protocol (MCP) is a standard for connecting LLMs to enterprise data sources in real time, to ensure compliant and complete GenAI responses.