







.jpg)

Table of contents
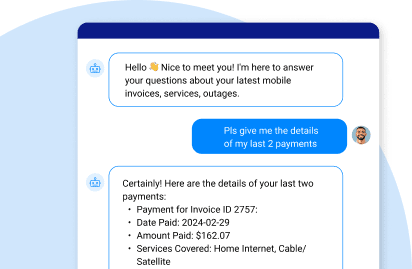
Imagine a call center agent asking an AI assistant, “Why is there a discrepancy in this customer’s latest invoice?” and getting a clear answer instantly.
A look under the MCP hood
Answering an operational question – accurately, in real time, and grounded in trusted enterprise data – is no trivial task. Because that basic question-answer process poses many different challenges, like:
-
Parsing the natural language prompt
-
Understanding the business context (a customer query)
-
Identifying which systems contain the relevant data (CRM, finance, support)
-
Querying those systems in real time
-
Harmonizing the results into a clean, coherent view
-
Injecting that context into a prompt that a Large Language Model (LLM) can understand
This 6-step orchestration layer is increasingly referred to as MCP AI, a foundational pattern for enterprises implementing AI.
The MCP client-server approach is essentially the missing link that makes LLMs useful in real-world business environments. But, MCP must work in tandem with a data layer, often enriched by generative AI (GenAI) frameworks – like Retrieval-Augmented Generation (RAG) or Table-Augmented Generation (TAG) – which fetch fresh enterprise data to enable more informed LLM responses to user queries.
End-to-end context from user to model
To understand how MCP works, let’s have a look at the full AI context stack behind LLM-powered interactions:

In the above diagram, steps 2 and 4 – intent recognition and task planning - and - prompt construction and injection – are handled by an MCP server, while step 3 – context retrieval and harmonization – is handled by the data layer. For example:
-
A user asks a question.
-
The MCP server interprets it.
-
Context is retrieved from enterprise systems.
-
The data is transformed into a usable prompt.
-
The LLM responds with an answer grounded in trusted enterprise data.
Now, let’s walk through the process step by step.
MCP context lifecycle
1. User input (interface layer)
The process starts when a user enters a prompt, such as: Why is ACME Corp at risk of churn? This input could come from a chatbot, agent console, app interface, or backend API.
2. Intent recognition and task planning (MCP layer)
The MCP server kicks in here to:
– Determine user intent (diagnose, summarize, query)
– Identify the target business entity (customer, device, order)
– Extract relevant parameters (customer ID = ACME123)
3. Context retrieval and harmonization (data layer)
The next step is pulling context from the enterprise’s underlying systems – often all at once. In our example, relevant systems might include:
– Salesforce: for account ownership and notes
– ServiceNow: for open support cases
– Amdocs: for product subscriptions and usage data
But this data is fragmented, with different schemas, IDs, and formats for each system. The data layer must route sub-queries, join the results, and normalize them into a single, coherent Customer entity.
4. Prompt construction and injection (MCP layer)
Once context is retrieved, the MCP server assembles the final prompt using a task-specific template. For example:
Customer: ACME Corp
Account owner: Jane Doe
Open tickets:
– Login error, opened 7 days ago
– Billing discrepancy, opened 3 days ago
This step involves prioritizing what information to include, trimming based on token limits, and structuring the prompt for the LLM.
5. LLM inference and response (model layer)
Finally, the constructed prompt is sent to the model. The LLM processes the input and returns a grounded, personalized, and actionable response.
Why MCP has become the de facto protocol for GenAI
A Practical Guide
Model Context Protocol (MCP) is a standard for connecting LLMs to enterprise data sources in real time, to ensure compliant and complete GenAI responses.

Why the MCP pipeline is challenging but worth it
Delivering accurate, real-time, multi-system context has the following challenges:
-
Latency
Traditional systems weren’t designed for conversational AI workloads.
-
Fragmentation
Data lives in different formats across different tools.
-
Structure
LLMs require tightly scoped, coherent prompts, not raw data dumps
-
Governance
Many of the datasets contain Personally Identifiable Information (PII) and other sensitive data which must be masked before reaching the LLM.
Without addressing these issues, LLMs hallucinate, offer vague answers, or simply fail to respond.
Business entities to the rescue
One increasingly popular strategy is to organize context around business entities (like Customer, Order, or Device), rather than task-specific APIs. The entity-based approach offers several benefits:
-
You get a complete picture in one call (not 5).
-
Data retrieval is predictable and composable.
-
Governance is easier when each entity can be cached, masked, or isolated as needed.
The result is faster response time, less noise, and more accurate AI behavior.
Back to our customer churn example
-
User asks: Why is ACME Corp a churn risk?
-
MCP parses: Intent = risk explanation, Entity = customer
-
Data layer retrieves:
– CRM – account owner, last interaction
– Support system – open issues
– Product logs – usage drop
-
Data layer harmonizes into a clean customer object
-
Injects into a prompt template
-
LLM returns a grounded churn-risk summary
Design considerations for building MCP systems
If you're designing or evaluating your own MCP-powered architecture, keep the following in mind:
-
Latency targets
Can your stack return context in less than 300ms?
-
Token budgeting
What’s the max context you can include per task?
-
Decisiveness
Will your prompts be session-aware or stateless?
-
Governance
Are you redacting PII and respecting data access rules?
-
Prompt templating
Are templates easy to maintain, reuse, and A/B test?
How K2view powers MCP in the enterprise
All the steps outlined in this blog – from parsing intent, through retrieving and harmonizing multi-source data, to constructing safe and relevant prompts – are challenging.
K2view addresses these challenges holistically with an enterprise-grade platform that offers:
-
A built-in MCP server to orchestrate runtime context flows
-
A semantic data product layer that manages real-world business entities
-
Real-time, multi-source data access using patented Micro-Database™ technology – one Micro-Database for each business entity.
-
Data guardrails that include field-level masking, entity isolation, and full auditability
With K2view, your LLMs are no longer guessing; they’re grounded in trusted data. They don’t just talk; they understand. They don’t just respond; they reason using the freshest, most secure and reliable data available.
In a world where AI must make decisions based on trusted enterprise data, K2view turns your stack from data-rich but context-poor into AI-ready by design.
Unlock the full potential of your LLMs with K2view MCP data integration
