





The complete guide to AI data agents
What are data agents? The bridge between agentic AI and enterprise data.
Last updated on April 28, 2026

See Agentic AI in Action
Go behind the scenes and see how we ground AI agents with enterprise data
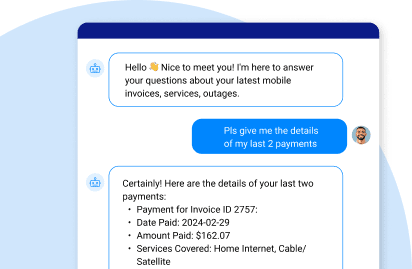

Start your live product tour
 Table of Contents
Table of Contents

02
What are data agents?
As AI systems become more agentic, enterprise data becomes a limiting factor. Business data is fragmented across operational systems, analytical platforms, and unstructured knowledge sources, each with different schemas, access rules, and freshness requirements.
AI agents need to reason and act using this data, yet they lack a consistent way to determine what data is relevant, how current it must be, or how it should be safely accessed and reliably assembled into context at scale.
This is where data agents come in. Data agents serve as a control layer between AI agents and enterprise data, determining what data is needed, how it must be governed, and how it should be accessed, then assembling that data into task-ready context for AI agents to reason over.
Analytical vs operational data agents
Data agents fall into two broad categories – analytical data agents and operational data agents – based on the task they need to perform and the latency and action requirements involved.
The two types of data agents solve fundamentally different problems. Analytical agents optimize for scale, history, and insight, while operational agents optimize for accuracy, latency, governance, and action. Confusing the two leads to unreliable systems and the wrong data architecture.
By aligning each data agent type with the appropriate data foundation, organizations can support both large-scale analytical exploration and real-time, data-driven decisioning and operational action.
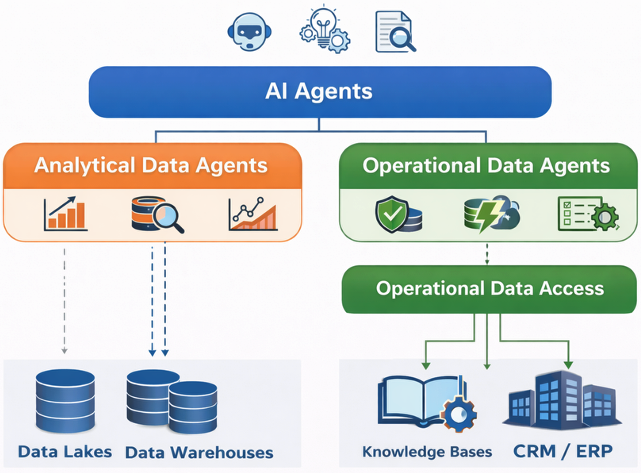
Analytical data agents
Analytical data agents typically query data directly from data lakes, data warehouses, or lakehouses, or access these platforms through data virtualization. This allows them to analyze broad datasets across time and domains, supporting tasks such as trend analysis, root-cause investigation, and forecasting.
Operational data agents
Operational data agents depend on a unified data access layer that combines data products for multi-source enterprise data retrieval with Retrieval-Augmented Generation (RAG) for knowledge search. They translate intent expressed in natural language into precise queries (SQL, APIs, and semantic search), then transform the retrieved data into coherent, task-ready context that AI agents can reliably reason over and act on.
Decoupling AI agents from data access establishes a clear control plane for context. It centralizes how data is discovered, governed, retrieved, and transformed so this logic is built once and reused everywhere, rather than re-implemented across every AI agent. This prevents duplication, reduces inconsistency, and allows AI agents to remain lightweight, portable, and focused on reasoning rather than infrastructure.
The immediate need for operational data agents becomes obvious when reading our recent survey on the State of Enterprise Data Readiness for GenAI. The study shows that enterprises are making meaningful progress toward production GenAI, with 45% planning to deploy or expand use cases in 2026. However, the findings make clear that data challenges still dominate, from guardrails and readiness to data quality, fragmented systems, and security and privacy concerns.

If you want your GenAI to work, start with your data
Grounding GenAI in enterprise truth demands AI-ready data that’s fresh, integrated, and contextualized.






-1.png?width=501&height=273&name=GenAI%20survey%20news%20thumbnail%20(1)-1.png)


